中国数字人文 Digital Humanities in China ![]()
![]()
![]()

大数据技术与古代文学经典文本分析研究
作者:刘石;转自:公众号 DH数字人文
前沿动态

刘 石 / 清华大学人文学院
一、背景与基础
文本数据分析一直是国外计算语言学、信息统计学等交叉学科研究的前沿热点。美、英、法、德等西方发达国家都已成立了国家级项目组或研究中心,致力于对包括《圣经》、莎士比亚戏剧、法国中世纪诗歌等多语种文学经典的内容分析,产生了一批引人注目的实证性与理论性成果。1950年代,瑞典汉学家高本汉也已运用统计学方法研究《红楼梦》的作者问题。近年来,这些交叉学科在中国获得了长足发展,并开始进入古典文学与文献学学科,在对古典文献的分词、标注等方面有了较多应用。基于深度学习的古典诗歌生成与分析系统、基于统计学模型的中文文本分析等技术在古籍文本切词、比对、计算等方面已具有初步成果。数据库在研究中日益发挥着不为人所熟知的诸多功能。
作为工具的计算机,已从文献检索时代进入到数据分析时代。计算机不仅能帮助我们从海量文献中快速检索到所需的资料,还能以数据为基础帮助我们发现问题和分析问题。顺应学科交叉融合的大趋势,有助于促进文理结合及创新突破。新一代关系型、结构化数据库结合大数据分析技术及相关方法与范式,既可为基础文科的研究提供数据、技术支持,也能够促进研究方法和范式的创新。随着数字人文技术的发展,数据分析的技术和方法越来越具针对性和有效性,能更清晰地揭示隐藏在文学史背后的作家与社会之间、作家与作家之间、文本与文本之间的直接与间接、显性与隐性的多种关联,能以全知型的视角系统整体地还原和呈现文学史的立体景观,改变传统的思维方式和研究范式。
清华大学在开展数字人文研究方面兼具历史传承与学科优势。1922年,梁启超已提出“历史统计学”,开“量化史学”风气之先。目前,清华大学人文学院、社科学院、计算机系、统计学中心等院系,已有多个研究团队在从事与数字人文相关的课题。清华大学人工智能研究院成立了以孙茂松教授为主任的“自然语言处理与社会人文计算研究中心”,引起了学界的高度关注。由本人主持的“基于大数据技术的古代文学经典文本分析与研究”于2018年11月立项,是国内第一个直接面对古典文学经典文本进行分析和研究的国家社科基金重大招标项目。

作为首席专家,我曾主持“中华字库”工程分项目“宋元印本文献用字搜集与整理”工作。“中华字库”项目致力于穷尽式收集所有古今汉字和少数民族文字形体,在专业、科学的方法和原则指导下,建立中国文字编码和主要字体字符库,最大程度地满足中华各民族各类古今文字数字化传输、检索和处理的需要。

我同时作为主编之一,协助清华大学中国古典文献研究中心主任傅璇琮教授,用六年时间规划、开展并圆满完成《续修四库全书总目提要》这一当代最大规模的古籍提要类著作,受邀参与此项工程的海内外学者近300 人,2019 年获得北京市第十五届哲学社会科学优秀成果特等奖。这些项目或著述从一代或多代之总体文献着眼,类聚相关资料,做研究性整理,研究的方式虽是传统的,与数字化时代文献整理的基本研究思路与方法却是相通的,即追求全面占有文献,通过大规模的类聚、排比相关资料,实现全面考证的目的。只是受到人工爬梳整理的工作方法、纸质文献线性排列及文本容量等方面的限制,尚无法做大规模的结构化整理、大量资料汇聚排列、人物关系网络化构建等方面的工作。

清华大学中国古典文献中心从2017 年起酝酿中国古代知识库建设工程,拟利用大数据时代背景下的技术手段和研究方式,分门别类地穷尽式汇集、聚类中国古代各类知识谱系,经纬交错地构筑基于历代典籍的知识架构,为今天及后人的古典学术研究提供一个高起点宽口径的通用平台。目前,张力伟研究员领衔的中心知识库建设团队全面提取古籍文献中人名、地名、纪年、职官、事件等重要的概念本体的工作已经开展,在析取概念独有的或共有的属性,依靠相同属性组建不同结构模式的基础上,形成了数十万条关系型数据库,这既是课题得以展开的数据基础,也是基于古代知识库平台进行研究的一个聚焦式的尝试。[1]

大数据及其相应技术已经成为当代科技发展的重大标志,渗透到社会的各个领域,对社会知识体系及思维方式产生了重大影响,而基于这一技术对古代文学经典文本进行高效和深度分析,可将文学研究纳入一个更宏观的视野,提高研究结论的精准性、稳定性及可验证性,促生新的研究理念、方法与范式。但总体来看,古典文学研究领域对大数据的运用目前还停留在数据建设和全文检索的初级、表层阶段。
二、目标与思路
经典文本是古代文学学科的基石,以先秦至明清品类纷繁的古代文学经典文本为研究对象,利用计算机、统计学等学科的新兴技术手段,发掘依靠阅读经验难以发现的文本组织特征及相互关系,可定量统计、分析及归纳单凭人力难以解决的诸多问题。选择先秦至明清时段古代文学经典文本进行相似性、关联性、规律性研究,有望解决古典文学研究领域长期存在的疑而难决的作品归属、作品辨伪、异文辨析、修辞特色、风格生成、题材变迁、因革影响等方面的问题:
一是重新验证已有成说的经典史论问题。比如,提出“文必秦汉,诗必盛唐”的以明代前后七子为代表的文人群体,其诗文创作是否落实和如何落实其文学创作的主张?利用共词分析、语义分析、人物事件交杂等技术方法,正可尝试创新分析和解决诸如文体形式、社团流派、人物关系、情节演进、阶段特征、历史影响等问题。
二是解决人力难以彻底解决的疑难问题。为作品归属、重出异文、改编续写、风格流派、文类划分等提供新的证据、思路与方法。如唐宋诗“体格性分之殊”的判断,诗词曲三种相近文类格律、用韵、题材、语词、典故、句法、意象、风格的穷尽性统计,为定性分析提供数据支撑,提高研究结论的精确性、稳定性及可验证性。
三是超越主观感受与印象分析层面,科学梳理文学发展史长时段中存在的特征、规律及作家作品之间的各种关联。比如陆游诗近万首,词自中唐产生而历经各代,他或它们的题材、修辞、风格变化轨迹究竟如何,数者之间的关系怎样?通过对一个作家或一类作品的深度学习,发挥其文本比对、关联分析等技术优势,追踪挖掘以往不曾注意到的迹象或线索,能够大幅度提高文学经典研究的可靠性与科学性。
以上研究设想的实现,建立在两个基础之上。
其一,古代文学经典文本数据的结构化。采用大数据语义分析中常用的联系算法进行关键词管理。同时,利用已有人名、地名、职官、俗语、典故等专名词库进行辅助,提高分词、标注的速度及准确率。发挥精细化语料库的功能,使其从“字联网”形态进入到更深层的“意联网”脉络,借以快速检阅各种庞大的文类和文本, 发掘其中的隐含信息和潜在规律。
其二,利用大数据技术构建多样化文本分析系统。运用深度学习的方法和技术手段,对古代文学经典文本进行多维度、多模块和多属性分析,识别文本中的关键词,针对不同问题选定语料库和设定算法。通过搜寻、比对、聚类等方式, 评估不同文本语段之间的相似度和相关性,构建符合学科规范的立体知识网络。
大数据分析可以让研究者具有“上帝视角”,做到整体和系统地重新认识经典文本的形态特征、生成演变和相互关联,从而带来研究视野、观念和方法的转变。不过,大数据毕竟只能作为学术研究的辅助手段而非替代方式,文学研究中新技术手段的应用需要充分依靠计算机科学和统计学的专业研究人员,文学性问题的提出和分析处理却不可能完全交给机器,相反,从问题的设置到语料的选取再到分析结果的解读、意义的阐释、体系的建构等,都将由古代文学和文献学相关领域高水平的专家学者完成。
三、内容与结构
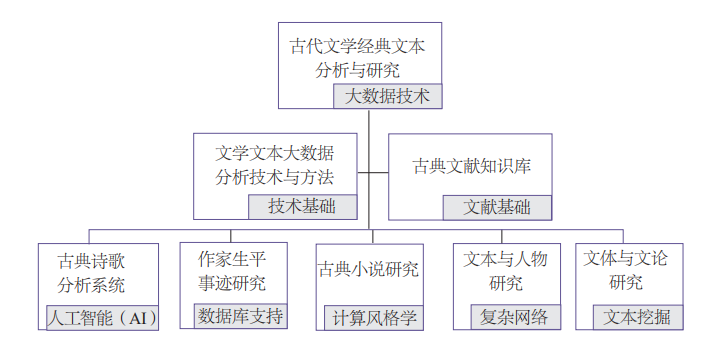
清华大学中国古典文献研究中心通过承担及参与“中华字库”工程、“中华基本史籍知识库”等项目,积累了较为丰富的可用于科研的数字文献资源。同时,拟与哈佛大学“中国历代人物传记资料”(CBDB)、中文在线集团等合作,在进一步充实资源的基础上进行数据化、结构化加工。实体名词的识别一直是中文信息处理的难题,而古籍中的实体名词数量及类型繁多,因此除了不同时期的核心词库,我们还拟建设适用于所有古籍的文献题名词表、历代人物词表、称谓词表、官职词表、年号词表、地名词表及古代虚词表,实体名词词表的建立提高了分词的准确率。本课题将以大规模中国古籍文本为研究对象,通过对古籍进行整理、标注、自动分词等处理,并采用新的可视化分析方法对古籍文本进行挖掘,创建一个可辅助研究者进行以文学文本研究为主的古籍实时统计分析平台。

在依靠经典文本库、运用大数据技术手段的前提下,我们列出古代文学文本研究的问题清单,对文本及基于文本的相关问题进行计算机与统计学的深度分析,再结合文学史论及具体作品对分析结果进行阐释和研究。现阶段数字人文研究的主要技术方法,包括机器学习与人工智能、数据库建设、计算语言学、社会网络与地理信息系统、数据与文本挖掘等方面。[2]这些技术方法在人文社科领域正在被推广使用,且取得了突破性成就。我们将有针对性地创建和改进算法和理论模型,以增强解释的准确性与有效性。
我们所聚焦的古代文学经典文本研究的主要问题,具体而言,有以下几个方面。
(一)大数据时代的古代文学文本分析技术研究。利用已经成熟的统计学、计算语言学等技术方法,构建适用于文学文本研究的统计分析、数据挖掘与算法模型。同时,针对古代文学文本的特点,研发具有针对性和适用性的工具,并在此基础上构建分析平台。
(二)基于人工智能技术的古典诗歌分析系统构建。以经典诗词文本为研究对象和文献基础,通过机器学习和模型构建,衍生出模拟创作和研判作品的计算机系统,输出多维度、研究型、体验式经典文本交互系统。预期完成的系统不但可以为经典文本的研究者提供时代、风格、用韵等专业领域的判定,辅助经典文本整理中的辨伪、辑佚、系年等工作,还能提升普通读者的人机互动学习和创作体验。
(三)基于文献知识库的汉代至元代作家生平事迹研究。在中国古代文学经典文本库及知识库建构的基础上,促进古代文学经典文本数据的结构化,发挥精细化语料库的功能,快速搜检各种庞大的文类和文本,发掘其中传统汉代至元代作家研究中未曾触及的潜隐信息,为文学经典的解读提供更为广阔坚实的基础。
(四)基于计算风格学的明清小说研究。从语言学的角度探讨词汇特征、语法特征和语义特征在明清小说中所起作用和所充当的功能角色;从数学角度发现适宜特征选取和特征比较的统计模型;从计算机科学角度优化假设检验、聚类、分类和深度学习算法,自动对小说作品进行词汇、句法和语义的计量风格特征统计和分析。尤其以中国古典小说名著《红楼梦》《三国演义》《水浒传》《西游记》《三遂平妖传》《金瓶梅》等为研究对象,将语言学、数学和计算机科学的相关理论相结合,从交叉学科的角度研究四大名著的风格特征。多方面多角度运用科学的研究方法,来判断《水浒传》《西游记》和《红楼梦》后40 回的作者归属等问题。此项研究,亦对其他存在作者争议的作品分析具有借鉴意义。
(五)基于复杂网络的文本与人物研究。以唐宋时期经典作家作品为主要研究对象,兼及明清小说,围绕文学文本生成、文学文本经典化、人物生平及社会网络分析等问题展开研究。以韩愈、苏轼等个案为例,详细考察和直观呈现韩、苏二人真实可靠的社会网络与社会交往过程。借助于传统的小说叙事、修辞分析以及文体测量手段,从文体学和文学社会学的总体视角对元明以来的长篇章回小说经典文本做长时段、总体性考察。考察大规模叙事性文本中所形成的人物关系网络在关键节点和群体层面可能具有的结构性特征,以及近代以来叙事性文体观念、虚构性叙事文学的人物角色功能变化等问题。
(六)基于文本深度挖掘的文体与文论研究。基于数字人文领域中广泛使用的“文本挖掘”方法,对不同文类文体的语言特征及其文本功能进行分析,尤其对声韵词句特征、格律形成演变、情感表达等做出新的探寻。利用文本深度挖掘得出的数据,对文学研究中重要的两个领域“文体”与“文论”中出现的重要论题进行具体而微的专题研究。
各专题之间的关系如下:
四、相关研究
在开展重大项目研究的同时,我们还申报了“清华国强研究院‘人工智能’ 研究项目”,尝试创建“中国古典诗歌分析系统”与“中国古典诗歌文献数据库”。目前主流的古典诗歌数据库尚存在数据不大、底本不精、预先分类工作欠缺等问题,而高质量的AI 古典诗歌分析系统仍付阙如,人机互动和数据共享开发仍然处于起步阶段。我们期望借助清华大学的技术优势,完善和优化诗歌文献数据库,充分运用大数据技术,以期优化学科交叉顶层设计,使用专业技术进行针对性研发。
以经典诗词文本为研究对象和文献基础,在处理、阐释文本的基础上,通过机器学习和模型构建,衍生出模拟创作和评判作品的AI 系统,并与“文本生成”“文体与文论”等领域的研究成果形成链接,输出多维度、研究型、体验式经典文本交互系统,为经典文本的研究者提供时代、风格、用韵等专业领域的判定,辅助经典文本整理中的辨伪、辑佚、系年等工作,同时提升普通读者的人机互动学习和创作体验。
我们今后拟从下面几个方面同时开展工作。
一是古典诗歌分词及知识图谱。运用计算语言学和自然语言处理技术自动实现针对古典诗歌文本的词汇抽取、分词和关联分析。开发适合古典韵文特别是诗歌的文本分析模型和工具;通过共现分析、关联关系挖掘等技术手段,在诗歌及其语言以及相关各文化要素之间建立关联关系,并上线首个“古典诗歌知识图谱”。
二是古典诗歌的声律模式研究。古典诗歌在声韵、平仄等方面符合某种较为严格的规律和范式,但实际上也有不少突破经典声律模式的案例。我们将尝试采用大数据分析的方式,为海量古典诗歌建立声律统计模型,处理古音韵及多音字等问题,发现“拗救”等变体的规律和原则,对古典诗歌声律规律实现穷举和归纳,突破传统研究范式的局限性。
三是面向溯源的中国古典诗歌风格研究。诗歌的“风格”问题可谓古典诗学的元问题,时代之争、地域流派、影响流变等诗学问题,无不与此相关。我们将借助海量古典诗歌样本,综合运用统计学习方法和深度学习技术,建立可对抽象的诗歌“风格”进行表示、量化、计算、溯源的新技术、新方法,为解读传统人文经典的风格特征、人物塑造、本事源流、影响追踪等提供新的途径。著名数学家邱成桐先生提出,能否经由《红楼梦》中诗词作品的风格、艺术和思想、内容溯源,探寻作品中的人物原型。这是一个有创意的想法,我们亦将就此试做努力。
从学科交叉的角度来看,文学研究所讨论的文学本体及其文学性,向来是基于阅读经验的文学研究,这一“经验”很难为人工智能所复制。本研究试图以计算的方式分析和理解此“经验的文学性”,以期获得可量化甚至为机器所学习的“计算的文学性”,若能达成这一创举,则有望成为人工智能在文学艺术领域的进步台阶。配合本研究开发的阶段性工具,如“古典韵文分词工具”“计算风格及匹配方法论”“古典诗歌声律模型”等,皆具有技术层面的探索意义。本研究的预期目标之一“古典诗歌知识图谱”,亦属具有创新性的研究。
目前可用于统计分析的关系型古籍数据库建设还比较薄弱,适用于人文研究的分析工具、分析方法、分析模型还相当有限。近年研究依赖较大的一些电子古籍库主要用于检索,还不是结构化的能进行统计分析和再生知识的数据库。未来的学术研究很大程度上将是基于数据驱动,数据平台、技术平台和研究平台三位一体的模式将成为常态。在结构型数据库和数字人文时代,研究成果将立足于数据和分析,同时也将加载到数据平台被分享。超越现有基本电子古籍库的新一代关系型知识库正在出现。清华大学数字人文研究的中长期目标将致力于围绕“中国古典诗歌分析系统”与“中国古典知识库”(Chinese Classics Knowledge Base,简称CCKB)等科研项目和重大工程开展工作。
经典的传承与研究关系到民族文化与精神的塑造,具有不可估量的重要价值。利用大数据技术研究经典文本,将会大大提升古典文学研究的科学化水平。大数据技术作为一门新兴技术,不仅能改变我们的思维方式,还有可能在相当程度上改变我们的世界观。当然,由于人文社会现象的复杂性、多样性,尤其是精神交往和思想沟通具有个性化、非量化和多义性的特点,完全依赖大数据的人文社会科学研究又很容易陷入科学抽象弱化、人文关怀缺失和情景化的研究逻辑被打破等危机,如何避免陷入这些危机,也是需要我们同时关注的问题。
本文为国家社会科学基金重大项目“基于大数据技术的古代文学经典文本分析与研究”(18ZDA238)阶段性成果。
注释:
[1]张力伟:《走向深度学习—大数据背景下“中国古典知识库”的构想》,《光明日报》2018年10月15日, 第13版。
[2] 刘石、孙茂松:《大数据时代的古典文学研究》,《光明日报》2018年10月15日,第13版。
编 辑 | 严程 穆荷怡
原刊《数字人文》2020第一期, 转载请联系授权。