中国数字人文 Digital Humanities in China ![]()
![]()
![]()

机器学习与人文视角
作者:特德·安德伍德 ;转自:公号 DH数字人文
概念与实践

特德·安德伍德 / 美国伊利诺伊大学厄巴纳分校信息科学学院和英语系[1]
肖爽(译) / 爱尔兰科克大学数字艺术与人文系
陈大龙(校) / 浙江大学国际联合学院(海宁国际校区)
————————————
摘要:数字不只衡量客观事实,也适用于解释视角差异。定量方法可以很好地适用于比较的、相对主义的和阐释学的问题,这就是计算阐释学。由定量统计建立起的特定类型的模型,利用在另一个时空产生的文件,重建一个已经消失的世界视角,这与人文主义者对待过去的传统方法十分相似。不同的是,这种监督模型可以对新的证据做出预测——它如同人类观察者那样,也会犯一些能揭示问题的错误。通过研究这些错误,我们可以找出视角之间的视差,测量没有数字就很难表示的程度差异,这正是机器学习给人文研究带来的新的机会。
关键词:文学测量 视角差异 定量方法 机器学习 计算阐释学
————————————
主持人按语:
特德·安德伍德近期发表的文章《机器学习与人文视角》,是《美国现代语言学会会刊》聚焦数字人文问题中的系列文章的重头戏。这篇文章向文学学者介绍了使用机器学习(或者称为“人工智能”)进行文学分析的可供性(affordance),特别是在分析英语小说方面。长久以来,文学学者都拒斥定量研究,因为他们认为这些方法是将文学的复杂性简化成了一组单一维度的测量或数值。安德伍德承认,在历史上,定量方法对这个学科确实不太有用。例如,“美丽的”(beautiful)这个词在弗吉尼亚·伍尔夫的《达洛维夫人》中出现的次数并不能告诉我们与这部小说主旨有关的任何信息,也不能告诉我们它与其它类型的小说(比如现实主义作品)有何不同。但是,安德伍德也论述了最近计算与数据科学的进步,特别是新的机器学习算法的发明,为学者使用数字化方法研究文学提供了更多产出成果的机会。
安德伍德论述道,实际上,现在在理解和分析文学的方法方面,机器学习与文学学者之间的差距比我们认为的要小得多。机器学习实际上可以兼容像文本细读、历史分析这些现有的方法。因为机器学习算法并不是客观的,也并不追求客观性。算法在其被创造时就编码了一系列主观的选择,而这些主观选择则反映了更广的人类视角。这种方法的价值在于,我们可以使用更多不同的算法来研究同样的数据。重要的是,我们的方法是建立在被学者透明化的一组决策之上的,是规则性很强的、系统化的。正如安德伍德观察到的,我们可以大大扩展对自己感兴趣的任何一组文本的观察视角,比如英语现代主义小说。
在这篇文章中,安德伍德使用这种方法研究了文学中的几个例子,例如:安德伍德对比了男性作者和女性作者创作的小说之间的不同,还对比了侦探小说与科幻小说之间的差异。在每个案例中,他都既确认了我们已知的东西,又为我们展示了以往未知的东西。之所以我们能用这种方法学习到新东西,是因为机器学习算法可以在单一人类读者不可能达到的阅读和处理尺度上(数以万计的文本尺度上)运行。不过,安德伍德也再次强调了,机器学习提供的视角并不具有经验的客观性,也并非机器计算出的东西。相反,是人类建立了算法,算法发现的一切都反映了人类的视角,即反映了算法创造者的视角。机器只是简单地帮助我们看得更远更广,以一种新的、令人惊讶的方式扩大我们的文学观察视角。
(苏真)
引言
关于文学测量的争论比“数字人文”这个短语要早得多。现在用计算机研究的许多问题可以追溯到20世纪中期“用笔和图纸”工作时遇到的问题[2],对定量方法的反对可以追溯得更远。一个多世纪以来,批评家们观察到,数字稳定了关于过去的中立事实,但代价是使多样的视角扁平化了,而正是视角的多样性给历史赋予了意义。1910年,人类经验视角的特点是威廉·狄尔泰把人文科学从自然科学中分离出来的原因[3]。1973年,斯坦利·费什(Stanley Fish)也因此而反对对文学风格进行定量研究[4]。计算机可能会告诉我们乔纳森·斯威夫特(Jonathan Swift)使用了很多连接词。但费什认为,斯威夫特风格的文学意义可能因不同的解释群体而有所不同。
这些反对意见从未阻止文学学者在某些特殊的语境中使用数字,比如书籍史。但这类例外似乎只是证明了这样一条规则:知识分子的生活大致分为“解释”学科和“定量”学科[5]。当代关于数字人文研究的争论可能会让我们追溯同样的分歧。弗兰克·莫雷蒂提出,远读(distant reading)是一个用“解释一般结构”取代“解释”的项目[6]。批评家回应说,定量分析总是会忽略文学的重点,即突出“人类感知”的“无穷变化”[7]。双方似乎都在重申20世纪的共识,即数字只用于衡量客观事实,而不适用于解释视角差异。已经知道自己的作品具有解释性的学者可能会觉得可以跳过整个辩论,这是可以理解的。
在20世纪的大部分时间里,这是一种安全的政策。但是,定量方法和解释方法之间的界限总是可以渗透的,而且最近的知识进步使其易于跨越。由于学习算法依赖于具体而不是固定的定义,它们可以被用来为特定的创作或接受群体共享的默认假设进行建模。这种方法给定量研究提供了一种新的灵活性,允许学者们从过去特定的观测点来考察文化,甚至测量观测点之间的视差。文学史研究者只是在最近才开始发掘这些可能性。但已经很清楚的是,关于测量和解释之间的差异,我们对其所继承的假设需要被修正。为了理解出现的理论争论的形式,我们需要探索机器学习的透视用途。

一、从测量到建模
自从1973年费什对定量文学分析进行批评以来,许多事情已经发生了变化。现在电脑速度更快了,数字图书馆资源更丰富了。由于这些方面的变化很容易理解,数字人文学者经常用它们来解释人文学科对数字的日益依赖。批评家们认为这种解释是不完整的,他们的观点没有错,可以肯定的是,数字在大规模分析中往往更有用。但是规模本身并没有解决困扰早期定量研究形式的解释学问题,让文学史研究者感兴趣的概念至今仍难以测量,部分原因是它们的意义在不同语境中会发生变化。
要理解为什么定量研究能够在最近几十年取得真正的进展,我们需要在大数据的大肆宣传(和警告)之外挖掘,并注意到战略的微妙变化。其中一个转变已经在《美国现代语言学会会刊》(PMLA)最近的文章中描述过,就是暂时搁置计算机与经典文本之间的争论,以便重新将理论讨论集中在“模型”的概念上[8]。建立统计模型的人文主义者通常研究两个社会背景之间的界限,而不是试图测量一个稳定的概念。他们试图通过测量与之相关的差异来理解这个社会界限[9]。测量到的差异本身可能并不重要,它们可能包括标点符号这样的小事。探究的目的不是测量任何具有内在重要性的东西,而是定义一个模型——不同测量结果之间的关系——这个模型的重要性将来自于社会背景。
考虑一下代表性别的问题。无论我们把性别理解为一种表现[10]还是一种真正的“地位”[11],性别显然是关系性的。与其说这是一个关于主体的事实,不如说是关于主体与社会观众的关系。所以,当我们从一个文本转向另一个文本时,性别类别的意义也会发生变化。“男子气概”(masculinity)在1950年和1850年的含义可能不同,对女性和男性的含义也可能不同。具有这种关系字符的类别最好是间接地表示。定义或衡量男子气概是毫无意义的,因为这个类别本身就没有什么意义。但是男子气概的转变——当我们从一个时期或视角转向另一个时期——是一个模型可以阐明的主题。
最近我与戴维·巴曼(David Bamman)和萨布里纳·李(Sabrina Lee)一起写了一篇文章,通过比较两个世纪以来在人物塑造中使用的语言来探讨性别的转变[12]。一个名为BookNLP的程序将同一人物的名字进行分组,这样“玛吉·杜利弗”(Maggie Tulliver)和“玛吉”(Maggie)就可以被视为《弗洛斯河上的磨坊》[13]一书中的同一个人,然后识别出在语法上与每个人相关的单词。这种方法只给我们提供了人类读者可能提取的一小部分见解。在下面的段落中,程序链接到“玛吉”的单词只有我用加粗字体[14]标注的:
不停的闹声,大磨石继续不断的转动,给了她一种迷迷糊糊的、有趣的恐怖感觉(awe),好像她是在面对着一种不能控制的力量;麦粉永远在倾泻,倾泻出来;又细又白的粉末把样样东西的轮廓都弄得柔和了,把蜘蛛网弄得像巧夺天工的花边;麦粉发出来纯净的香味——这一切都使玛吉感到(feel)这个磨坊是一个和外界的日常生活(life)完全隔绝的小天地。蜘蛛尤其是她沉思的一个对象。她心里纳闷(wondered):它们在磨坊外面有没有亲属……[15]
可以说,乔治·艾略特(George Eliot)是在利用世外的磨坊里流动的、翻滚的能量,来描述玛吉的性格。BookNLP忽略了这个转喻,只知道玛吉是一个有“敬畏”(恐怖感觉[awe])和“生活”的人,是一个“感觉”和“好奇”(纳闷[wonder])的人。但这并不能准确概括出这段话所勾勒的玛吉。即使我们只捕捉到大致的轮廓,当我们在87,800本书和数以百万计的英文小说人物中使用BookNLP时,有趣的模式也会清晰可见[16]。
例如,我们可以问在描述中使用的性别符号是如何随着作者的身份而变化的。人们最终可能会对许多不同的作家角色提出这个问题——包括集体作者和笔名,以及顺性别(cis)和跨性别(trans)身份。但我们可以从那些公开被定义为“男性”或“女性”的作家所表达的性别观点开始。(公众身份不只是在扉页上表示出来,比如,艾略特最终以女性身份站出来,这里记录的就是女性身份。)图1中的两个轴用于测量词语在语法上与女性、男性字符相关联的趋势。简而言之,每条轴都是关于性别的一个特定观点的模型。两轴之间的唯一区别是,纵轴是衡量女性在书中体现的性别差异,横轴是衡量男性在书中所体现的性别差异。我们可以把图像看作是两个视角之间关系的模型。
图1的右上角和左下角包含的词涉及的性别内涵是一个广泛一致的主题。不管是谁写的书,女性角色往往有母亲和头发,说“哦”(oh)。男性化的角色往往有胡子和口袋,说“先生”(sir)。当我们沿着另一条对角线看时,事情变得更有趣了[17]。在左上角,我们找到了男人用来称呼男人和女人用来称呼女人的词语。原来,当玛吉对蜘蛛感到“好奇”(wondered)时,她正在做一些与作者自身性别特点相关的事情。记忆、思考、听觉和视觉也是如此,这些动词是主观性的明显标志。至于为什么作者声称身体的某些部位(脚、喉咙、头和胃)是他们自己的性别身份,在数据显示上就不那么明显了。
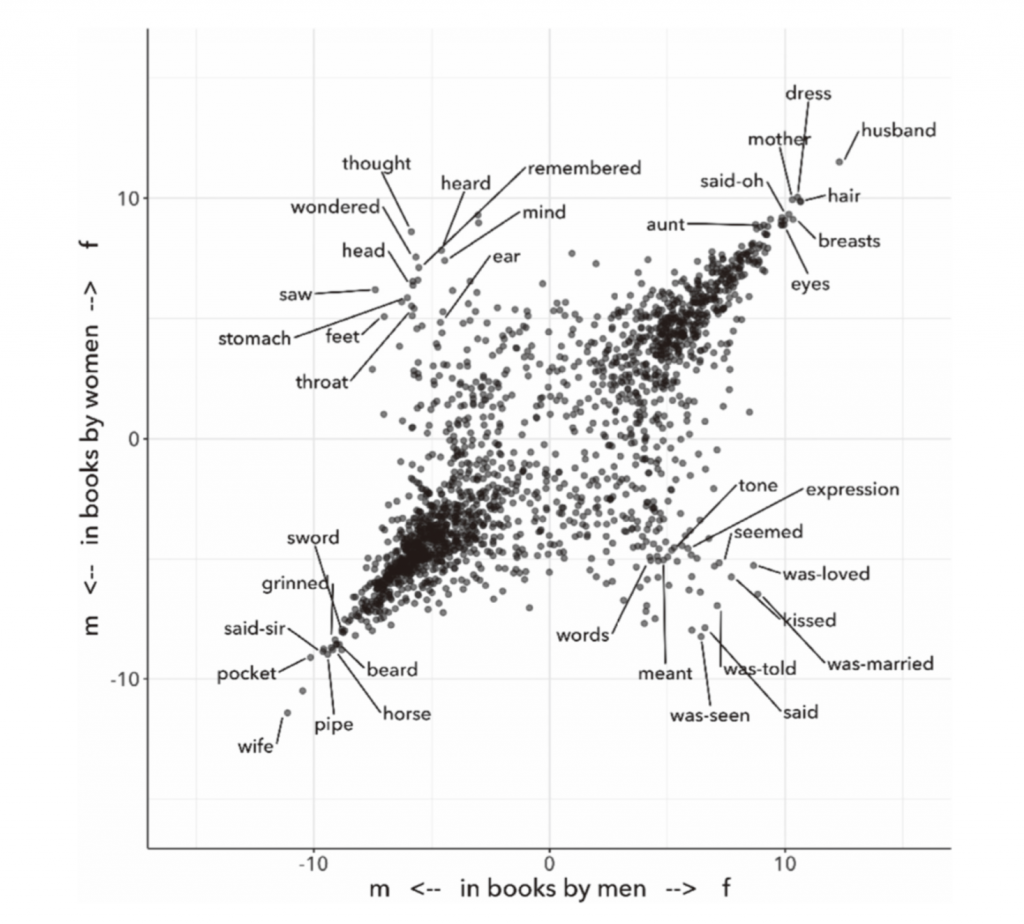
描述中使用的词语涉及的性别。该数据集包含1780年至2007年间出版的87,800部英文小说。在每个轴上,正数表示一个词在描述女性时被过多地表示出来,负数表示这个词在描述男性时被过多地表示出来。刻度为对数似然比(log-likelihood ratio)的带正负号的对数[18]。有许多重叠点的区域会看起来颜色更深。
在右下角,我们找到了一组男人用来形容女人和女人用来形容男人的词。这里可以看到异性恋模式,大多数作家在人物与自己的性别身份不同时,会更多地谈论结婚、接吻和恋爱。被动角色也很突出。我们用前缀“was-”来表示一个字符是动词的宾语而不是主语的情况。因此,“那天晚上,在黑暗中,她又看见(saw)斯蒂芬的脸带着热情、埋怨的可怜相朝着她”这句话对玛吉来说是“看见”(saw)的例子,但对斯蒂芬·盖斯特(Stephen Guest)来说是“被看见”(was- seen)的例子[19]。这个区域的其他语汇描述了一个角色是如何被看到的,即使这个角色是句子的主体:它们描述了一个角色的“表情”或“语气”,或者这个角色在另一个观察者眼中的“样子”。简而言之,很明显,女性作家倾向于外在地描述男性,反之亦然。
这种模式并不令人震惊,但这并不是说我们事先就知道了一切。一些细节仍不清楚,我仍然不知道为什么作家们声称胃和脚属于他们自己的性别。重要的是,期望主观性和被动性主要在男性作者的书中体现出来,这貌似是合理的,而女性作者的书可能会在男性和女性的角色中平等地分配“看到”和“被看到”。在其他许多情况下,性别的扭曲作用集中在男子身上。例如,男性创造出不平衡的角色组合,其中很少有超过三分之一的角色是女性,而女性则倾向于平衡她们的戏剧角色[20]。图1所示的视角变形基本上是对称的,两边都有盲点。既然我们已经追踪到了这种对称性,事后看来,这似乎是不可避免的。但这并不是我们真的已经知道的东西,也不是我们现在完全理解的东西。
我提供了图1作为当代定量方法运用的一个间接性的一个例子。这个图表不是试图定义性别,而是对主题的两个角度进行对比。我知道性别理论家会对图表的二元结构感到沮丧。诚然,这种二元性已经自我折叠起来了,这样是为了认识到社会体系是不同的,如果从体系中的不同位置来看的话。但这张图表仍然将性别认同的复杂现实简化为两个公共角色:男人和女人。坦白地说,我需要一个简单的图片来解释一个定量模型是如何表示一个视角的。但是这个方法并没有迫使我们止步于两个视角。我们也可以增加性别身份,提出交叉问题,或者探究性别的历史转变,就像我和我的合著者最近尝试的那样[21]。
米利亚姆·波斯纳(Miriam Posner)正确地将数字本体论的流动性描述为“数字人文根本的、未被实现的潜力”[22]。把这种潜力变为现实需要许多策略,本文的其余部分将探讨一个特别灵活的方法。与其把两个角色转变成四个或十个角色,我们不妨抛弃研究人员必须预先决定一组固定类别的这一整个前提。因为图1所绘制的数字和比例(A相对于B的表示)有点类似,所以它迫使我们将字符分成互斥的组。当群体被理解为排他性时,研究人员确实需要提前列出一个类别列表。但是还有更灵活的方法来构建和比较模型。由机器学习产生的预测模型不需要一个具有一致定义的排他性类别。他们所需要的只是一个能够指出他们心中所想的例子的观察者,观察者的人数没有限制。
二、倍增的视角
为了解释这种松散结合的方法是如何工作的,本文的其余部分将探讨类型的历史(the history of genre)——这是一个极大地得益于灵活性的主题。批评家曾经把文学流派想象成一组有限的自然文学类型,每一种都有一个统一的基本原理,就像达科·苏恩文(Darko Suvin)认为的将科幻作品统一起来的“新”(the novum)的概念[23],但20世纪晚期的历史主义(historicism)破坏了这种信心[24]。自1980年代以来,学者们倾向于将类型(genres)设想为“经验主义的,而非逻辑的”范畴——“出现在特定历史时刻的群体”,“不需要有单一的共同特征”,并且会随着社会条件的变化而“不断被重新定义或舍弃”[25]。
这种类型理论(theory of genre)之所以吸引人,是因为它似乎承诺了一种更灵活的文学历史,植根于人类生活不完美的连续性,而不是想象中的普遍存在。但该理论并没有提供一种方法来衡量在不同时刻形成的群体之间的相似性程度。所以文学史研究者仍然经常求助于一种要么全有要么全无的策略。例如,当代科幻迷可能会把19世纪作家玛丽·雪莱(Mary Shelley)和儒勒·凡尔纳(Jules Verne)的作品视为科幻小说。但是这个短语是在1920年代才首次出现的。19世纪的读者并不一定认为雪莱的黑暗故事跟凡尔纳的“奇特的旅行”(voyages extraordinaires)有关,或者是跟对乌托邦未来的幻想有关。在20世纪末,围绕着凡尔纳和H·G·威尔斯(Wells),所谓的科学冒险故事(scientific romance)的概念才开始形成。但是一些学者将科学传奇和科幻小说区分开来,认为后者只是在20世纪的后25年才形成的[26]。其他人则认为这两个概念都不稳定。根据最近的一段历史,“没有科幻小说这个东西,只有以科幻小说的形式生产、营销、分销、消费和理解文本的多种多样并且不断变化的方式”[27]。
对这些争论的语义特征的失望可能会把所有参与其中的人团结在一起。在这一点上,学者们知道类型并没有明确的边界。我们知道,我们的任务不是定义术语(或完全拒绝它们),而是追踪社会实践的逐渐变化。不幸的是,在追踪这些变化的过程中,很难排除这样一种可能性,即我们所感知到的连续性是由准备检验的有关系谱的假设所创造的。超越我们自己的假设总是困难的,尤其是对历史学家来说,因为时间只朝着一个方向流动。为了纠正回溯性偏见,一位谨慎的研究人员可能会在1895年把一箱21世纪的书籍寄给读者,并附上一封信,让他们挑出任何看起来像科学冒险故事的东西。但是,在那个时代无法把那样的一箱书寄出去。
但也许我们可以利用死者留下的文献来重现他们的选择实践?对此,计算机科学可能会有所帮助。机器学习的重点就是对缺乏定义、只能从例子中推断出来的分类实践进行建模。我们可能不知道如何去定义垃圾邮件,虽然我们能够在我们的收件箱认出它们。因此,垃圾邮件过滤器从一个训练集开始,该训练集由读者标记为垃圾邮件或未标记为垃圾邮件的消息组成。一种算法学习利用那些在实践中能够区分这些消息组的文本细节来为垃圾邮件建模。这是一种灵活的策略,擅长于复制人类行为,但当目标是保持中立时,这也是一种危险的策略。银行不应该使用机器学习来筛选贷款申请,除非它打算接受训练集里批准或拒绝贷款的人所做的所有假设。即使明显的种族和性别标记从数据中已经被去除了,试图复制人类选择的算法也会发现,在地址和职业中隐藏着的代表种族和性别的信息。
但是,历史学家需要做的,正是捕捉隐含在一组特定的人类选择中的不公平的、定义不明确的假设。文学史研究者们知道,他们想要重建的实践并不是中立或客观的。例如,我们知道,当读者要把一本书归类为科幻小说或奇幻文学时,作者的性别可能会起作用。我们为类型建模的目标不是重写历史,好像它是公平的似的,我们的目标是展示出真实的选择实践,这样我们就可以追踪不同地点和时间的角度之间的相似程度。尽管看起来很奇怪,但机器学习正适合于这一目的。
机器学习是如何工作的?本文中使用的算法受到监督,这意味着它们学习的文本都是被人类读者标记过的。关于类型的每个观点都被表示为一种模糊的边界,这种边界将被赋予某个类型标签的文本与未被赋予该类型标签的文本区分开来。如果文本是三维空间中的点,那么这个边界就是一个倾斜的平面,这个平面将大多数标有“奇幻”的作品与大多数标有其他标签的作品分隔开来。我之所以说“大多数”,是因为所有的统计模型都不完美。我们会对它们犯的错误感兴趣。但在探究错误之前,我们需要先了解文本是如何表示为空间中的点的。什么变量可以算作高度或宽度?研究人员可以尝试巧妙地定义适合特定类型的变量。例如,为了辨识奇幻文学,我们可能会问,这个情节有多少依赖于魔法?但这可能会带来一些冒险的假设,因为我们并不真正知道魔法对于奇幻文学是必不可少的,也不知道如何将魔法与“超级先进的技术”[28]区分开来。
不过,请记住,贷款申请模型不需要明确提及性别或种族,就可以吸收人类的偏见。同样地,尽管我们可能不知道对于特定的读者,奇幻文学是由哪些属性定义的,但我们可以预期,其中的许多属性会在文本的某个地方留下痕迹。因此,一个模型可以简单地计算单词的数量,将每个单词的相对频率视为一个维度,比如高度或宽度。因为小说的语汇包含数千个单词,这将产生一个有数千个维度的空间,但是这样的空间仍然可以被超平面分割[29]。
持怀疑态度的人可能会抗议,定义类型的不仅有措辞,还有情节、背景和主题——这是对的。但本文的目的不是定义类型。相反,它使用模型把类型作为接受的实践来展示,这样我们就可以比较不同时代的实践。模型通过重塑特定读者或读者群体的选择实践,来展示一种主动和具体的接受。由一组被读者标注的文本训练出来的模型,它不仅能识别被训练的文本,还能识别被同一读者分配到同一类型的其他文本(事实上,为了避免循环论证,模型总是在这些更具有挑战性的例子上进行测试,而不是在训练它们的例子集合中测试)。尽管措辞可能不能提供一个令人非常满意的关于类型的抽象定义,但它足以支持这种具体的再创造。例如,仅基于单词和标点符号的统计模型可以将玄幻小说(mysteries)与其他类型的作品区分开来,准确率达93%。如果我们仔细观察这些模型的内部运作,我们会发现,它们在很大程度上依赖于问号和表达不确定性的语汇,比如“任何人”(whoever)这样的语汇。虽然这些细节从技术上来说是措辞上的问题,但它们显然也受到了玄幻情节(mystery plot)中疑问结构的影响。事实证明,许多形式模式都会留下这种语言痕迹。因此研究人员发现,他们不需要直接表现情节和角色,就能够预测由情节和角色塑造的人类判断[30]。
定量模型可以使我们对于类型的历史认识更丰富。为了说明这可以有多丰富,本文的其余部分将从关于科幻小说和奇幻文学的视角进行一系列比较[31]。这些类型令人费解,但会对我们非常有用。它们的历史被写成了许多不同的方式,有时甚至坍缩成一个关于推想小说(speculative fiction)的故事。要是写一本书对这段历史进行研究,或许可以从数十部书目或数千篇书评中找到证据,还可能探究不同民族传统之间的差异。这篇文章只能更谨慎地阐述一种新方法的潜力,所使用的证据种类也会比较受限。我将关注英文原著(加上一些有影响力的翻译作品),并只比较少数几个观点。
最重要的资源来源是图书馆本身。来自HathiTrust和OCLC的类型分类(genre classifications)让我找到了数千本被图书管理员标记为“奇幻文学”(fantasy fiction)和“科幻小说”(science fiction)的书籍[32]。但图书馆员所做的类型标签几乎都是在过去40年中确定的。当这些标签与1980年以前出版的书籍联系在一起时,它们可能会投射出一种人们对文学实践最近才有的视角,而当时人们对此的理解则是不同的。因此,我也找到了更早的资料——1934年写的一篇学位论文、一份1911年的图书馆流通目录[33],以及一些早期的批判性研究和参考书目。最后,我用HathiTrust的600卷小说随机制作了一个背景集,其中不包括那些标注为科幻或奇幻的。综合所有这些资料,我们得到了1,581卷,在大多数情况下标明了首次出版日期。一部1,581卷的合集,并不能完全涵盖类型的历史。但是,无论是近期的倡导者还是其批评者,都夸大了定量调查可穷尽性的观点。事实上,很久之前的读者总是使用示例,并且通常更感兴趣的是对示例之间的差异建模,而不是对整个库乱下断言。
那么透视模型(perspectival models)能告诉我们有关科幻小说或奇幻文学的什么方面呢?那些能够预测类型的语汇提出了一些有趣的问题。例如,“奇幻”(fantasy)通常可以用“童话”(tale)、“阳光”(sunlight)和数字“七”(seven)来识别。但我在这里只简单地提到个别的词,因为这篇文章并不是试图为科幻小说或奇幻文学提供一个单一的、稳定的定义。相反,它比较了多种模式来探索类型历史的视角问题。研究人员发现,计算机最容易模拟的类型也是人类读者容易达成一致的类型[34]。因此,比较不同模式的强度可能会为关于类型相对稳定性的争论提供新的线索。
让我们从过去40年来图书馆员所定义的模式开始。事实证明,被图书管理员称为“科幻小说”(science fiction)的书籍——从1870年到2010年平均抽样,再加上19世纪更早期的一些例子——可以用一个单一的模型识别,准确率为89.9%。这是令人惊讶的,因为评论家们并不一定同意1920年之前的作品是真正的科幻小说。此外,我们倾向于认为这种类型的显著特征是技术,而技术变化很快。凡尔纳提到的发明在今天几乎都不再是科幻的了。但是,这一类型的语言模式不太关注潜艇或火箭船,而更关注崇高和含糊不清的一般修辞,其特征是大量、故意模糊的名词,如“物”(thing)和“生物”(creature),以及动词“眨眼”(blink)和“摸索”(groped)。从雪莱到金·斯坦利·罗宾森(Kim Stanley Robinson),这些作家都可以用这种修辞联系在一起,因此“不存在科幻小说这种东西”[35]这一论断似乎夸大了这一类型的易变性。
在过去,奇幻(fantasy)似乎比科幻更稳定:剑不会像射线枪那样快过时。但是,当我们把当代图书馆员称之为“奇幻”的所有书籍归类时,只有84.5%的几率能识别出它们。这与科幻小说(89.9%)的准确性之间的差异听起来可能并不大,但随着时间向更早推移,这两种类型之间的差距越来越大(图2)。这种不断扩大的差距表明,科幻小说的界限在我们现在称为奇幻(fantasy)的类型界限之前就已经巩固了。事实上,对于1900年以前出版的作品来说,“奇幻”甚至都不是一个合适的标签;在那个时期,准确率下降到77%,人们可能会怀疑那些给“奇幻”贴上标签的图书馆员是否使用了一个时代错误的概念。在图2中,科幻小说和奇幻文学之间的差距并不是唯一有趣的模式。从1875年到1985年这一上升趋势意味着这两种类型的小说更容易从图书馆中的其他小说中分离出来——尽管对于科幻小说来说,这种变化非常微妙。这些模型越来越精确,有几种解释。我们可以看到与情节或主题相关的通用文体惯例的合并:一个更明确界定的文体类型可能更容易识别。但是由于图2中使用的类型标签是最近指定的,所以也有可能(至少在奇幻文学的情况下)这些标签只是更适合20世纪晚期的文学,而不是早期的文学。
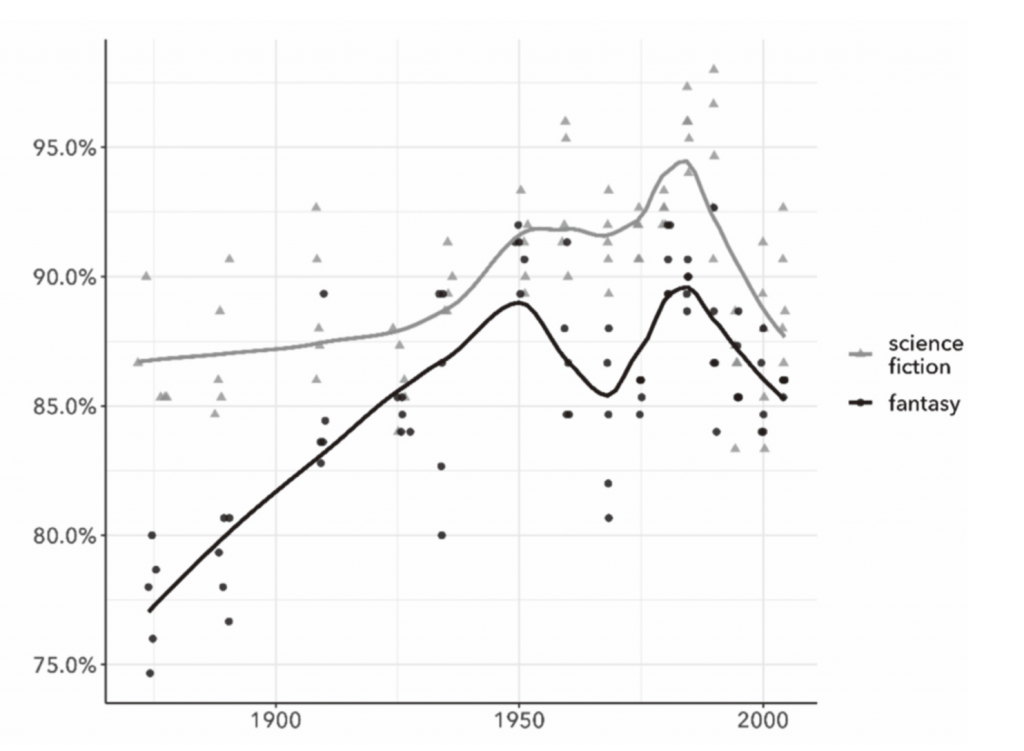
模型识别被图书馆员标为“奇幻”(fantasy)和“科幻”(science fiction)书籍的准确性。每一个点代表由一定时期的随机样本的文本训练得来的一个单一模型。每个模型包含150个文本;在这些文本的平均发布日期绘制点。趋势线是通过(任意数量的)局部加权平滑点绘制的,对此应该谨慎看待。
图2中令人惊讶的部分不是类型变得更容易辨认,而是这种变化在科幻小说中是如此的微妙——人们常说,在20世纪上半叶一个明确的时刻之前,科幻小说并没有作为一个具有一致性的类型而存在。1926年,《惊奇故事》(Amazing Stories)杂志的创刊为一个颇受欢迎的起源故事埋下了伏笔,因为该杂志与“科幻小说”这一术语是同时出现的[36]。加里·K.沃尔夫(Gary K. Wolfe)甚至把其类型巩固起来的时间拖得更久,他认为“科幻小说一直未能成为一个具有一致性的类型”,直到1940年代早期,口袋书(Pocket Books)才赋予了它形式[37]。但是图2中的波动看起来并不像是一个新的类型的出现。相反,在凡尔纳和威尔斯的时代,科幻小说似乎已经相当一致——几乎和今天一样一致,而且比今天的奇幻文学(fantasy)还要一致。在20世纪下半叶,这一类型的边界确实有一段时间变得稍微清晰了一些。直到1926年第一个晶种(seed crystal)形成,这种“未能成为一个具有一致性的类型”的局面才所有改变。
事实上,在过去35年里,界限的模糊化至少和之前任何科幻小说文体类型的巩固一样令人震惊。在对沃尔夫的科幻小说起源故事提出质疑后,我应该承认,最近的这种趋势确实非常符合他的书《类型消失》[38]的主题。正如沃尔夫所指出的,科幻和奇幻的混杂——既相互结合,又与文学主流相结合——最近产生了诸如“滑流”(Slipstream)“逆反超人”(Bizarro)和“新怪谈”(the New Weird)[39]这样的类型概念。他认为,这些变动是文体更广泛扩散的症候(symptoms of a more general diffusion)。“奇幻文学正在消失……扩散开去,渗入周围的空气给文学的氛围带来一种奇特的味道”[40]。图2中时间轴最后两种类型的曲线都出现了向下的转折,这为他的观点提供了佐证。
我一直在谈论科幻小说和奇幻文学,似乎这两个词同样适用于每个时期的作品,尽管已有证据表明,奇幻可能并非如此。视角方法(perspectival approach)的一个优点是我们不必相信连续性,在不同时间点上的观察者可能会在描述不同的事情。为了找出答案,我们可以建立不同的视角并进行比较。
就奇幻文学而言,甚至很难知道该选择哪个早期的视角,因为奇幻文学(除了别的之外)还与儿童文学和维多利亚时代的中世纪主义有联系。在这里,我只能追溯一个可能的谱系,追溯到20世纪早期被读者称为“超自然”(supernatural)或“神秘”(occult)的小说。多萝西·斯卡伯勒(Dorothy Scarborough)在《现代英语小说中的超自然现象研究》[41]中提到了一些作家,这些作家如今常常被引用为奇幻文学的原型,比如邓萨尼勋爵(Lord Dunsany)和威廉·莫里斯(William Morris)。但斯卡伯勒也详述了很多我们可能不认为是这种文体类型小说的书,像艾略特的《撩起的面纱》(The Lifted Veil)。尽管这些作品在我们看来可能是异质的,但我们可以通过一个思维实验的版本来测试它与现代分类的潜在相似性,这个实验要求过去和现在的读者对同一箱书进行分类。如果我们训练一个以斯卡伯勒的超自然小说为基础的模型,并要求它识别被图书馆员在过去四十年里标注为“奇幻”(fantasy)的19世纪作品,在斯卡伯勒作品集上训练的模型的准确率只比在最近标签上训练的模型低5%。显然,斯卡伯勒对超自然的概念和我们对奇幻的概念,两者之间存在着某种连续性。
然而,这种连续性并不能证明我们对奇幻文学的概念可以很好地描述19世纪的小说。相反,有强有力的证据表明,英王爱德华时期(Edwardian)[42]的分类更有利于组织这一时期。图2表明,我们对奇幻文学的概念并不符合19世纪作品之间的明确界限;对最近的标签进行训练的模型只能达到77%的准确率。基于斯卡伯勒批判性研究的模型稍微好一些(81%),其中最好的模型是基于爱德华时期的营销分类所隐含的类别的。例如,我们在穆迪(Mudie)1911年的流通图书馆目录[43]中以“神秘主义”(Occultism)为题收集的小说作品的建模准确率达到87%。
这种由大致同时代人构建的文体类别之所以能胜出,大概是最近的类型理论(genre theory)引导我们去期待的。对文体类型进行历史观念上探讨的学术风气的转向使许多理论家得出结论:根据定义,一个历史时期起组织作用的文体类型范畴,就是当时的观察者们所说的文体类型[44]。文体类型经常被重新定义的情况,往往缩小了同代观察者的范围。例如,莫雷蒂猜想,文体类型实际上是一种只持续“25-30年”的代际现象[45]。那些似乎持续时间更长的类型,可能只是一些被松散地应用于一系列不同代的现象的名称。我们已经有一些理由拒绝莫雷蒂的猜想,因为我们已经看到,对于一个单一的文本模型来说,识别跨越两个世纪的作品的文体类型亲缘关系是相对容易的。但是,比较对超自然、神秘和奇幻文学的不同观点,似乎仍然证实了在最近的类型理论中对作品同时代观察者的重视。而最精确的模型似乎是按书籍被写出来的时候的营销分类所训练出来的。
然而,当我们转向科幻小说时,故事就变得非常不同了。在爱德华时期的营销分类中,这一类型的任何版本都显得无足轻重。在穆迪的流通图书馆的目录中,五本“伪科学”(pseudo-scientific)小说被归入“神秘和奇妙”(mysterious and marvellous)的一个子类别,但这只是目录中的一个很小的细节,相比之下,四本组成“蛇之谜”(snake mysteries)这一类的书则被归入了更大的“神秘主义”(occultism)的目录[46]。尽管如此,我们还是看到那些被图书管理员回顾性地贴上“科幻小说”标签的书籍,实际上构成了19世纪文学实践中一个明显的划分。虽然这个类别是一个回溯性的推断,但它可以像作品同时代的目录和索引中实际列出的类别一样精确地建模。此外,我们有理由相信,尽管这个文体类别的名称发生了几次变化,但从19世纪到现在,它的组织模式相对稳定。我已经提到过,一个单一的模型可以高度准确地识别从这两个世纪的时间轴上的任何一点抽出来的书籍。对于更严格的连续性测试,我们可以将时间轴分成两半,然后比较这两半。我用《1817-1914年英文科幻小说》[47]中提到的书籍训练了一个模型,这个专题在“科幻小说”成为一个广泛接受的术语之前,由詹姆斯·贝利(James O. Bailey)在1934年写就。另一种模型是用被图书管理员列为“科幻小说”的1915年至1975年书籍训练的。当我要求每个模型对另一个模型的书籍列表进行排序时,得到了78%的平均准确率。对于一个在同一时期训练和测试的模型来说,就像用于创建图2的模型一样,这不会给人留下深刻印象,但是由于这些模型是在由不同观察者选择的作品上训练的,不同世纪的不同观察者会使用稍有不同的术语来描述,我认为这是显著的连续性。而类似的关于奇幻文学的测试则从来没有达到同样的稳定程度,即使我们允许作品同时代的图书馆员在时间轴的两部分选择作品。
简而言之,一种类似于20世纪和21世纪“科幻小说”的文学实践在19世纪确实存在,尽管当时的观察者对此很少关注,并且在他们注意到它的时候给它起了一系列不同的名字。诚然,历史延续性的证据推翻了我们有关视角方法的预期结论。我一开始假设来自不同时代的观察者描述了不同的物体,结果发现,在《奇异的旅行》、科学冒险作品等例子中,这些不同的对象结合比许多学者所认为的更为紧密。实验开始的时候的确是带着不同视角的理论前提的,但是一个精心设计的实验可以挑战它自己的前提。
我把科幻小说与超自然、神秘和奇幻文学的不同故事并列在一起,以表明类型理论(genre theory)所需要的框架应该比我们目前的讨论习惯所能提供的框架更灵活。形式主义(formalism)让我们相信文体类型是持久的隐含范畴类别的。历史主义(historicism)让我们相信,它们是由作品同时代的观察者明确定义的。这两种理论都不可靠,因为“类型”(genre)这个词可以涵盖广泛的现象——持续十年或几个世纪的模式(pattern)、只有在回顾中才获得一个名字的公开营销策略或文学实践。批评者并非没有意识到这种复杂性。我们已经在几个方面努力承认它,例如,通过区分“类型”(genre)和我们称为“模式”(mode)的松散模式。但即使是这种区别,也可能太粗糙了。哥特小说(Gothic)可以说开始是一种文体类型,而之后向外扩散,在某种程度上成为一种模式(model)[48]。此外,如图2所示,即使被理解为类型的实践也可能具有非常不一样程度的稳定性。
要描述文学史上各种各样的模式,我们需要一种能够承认程度差异的描述性语言。在承认这些层次时,数字并不局限于批判性描述;它们把它从固定的分类中解放出来。我已经证明了奇幻文学和科幻小说可以分别建模,但它们有时也会结合在一起,形成一个更大的传统,叫做推想小说(speculative fiction)。定量方法不需要在合并和分离的语义争论中停滞不前。相反,我们可以接受读者实际认识到的任何实践的现实,并简单地衡量不同实践之间的距离。事实证明,当被要求识别奇幻文学时,科幻小说的模型只会损失9%-11%的准确率(反之亦然)。因此,这两种类型的小说彼此之间的关系,比其中任一种类型与侦探小说(detective fiction)之间的关系更接近(在后一种情况中,模型会失去30%的准确性),但又没有奇幻文学和斯卡伯勒的超自然小说那么接近。在过去的30年里,奇幻文学和科幻小说的关系越来越密切。现在当一个文体类型的模型用于识别另一个文体类型时,只损失6%的准确率[49]。
三、测量视差
到目前为止,我们对类型的描述已经大致勾勒出来,但我们也可以使用数字来填充色彩和细节。因为上面讨论的模型对个别作品做出了预测,所以很容易就会问哪些作品代表了一个特定的视角——或者视角之间的特定对比。例如,如果我们想了解战前、战时和战后科幻小说的变化,我们可以以1910年至1939年出版的科幻小说为例来训练一个模型。然后,我们可以用战前模型去识别其后30年(1940-1969)出版的科幻小说,并将其预测结果与直接由后一种类型训练出的模型进行比较。这可以告诉我们,从战前的角度来看,哪些后来的科幻小说是最令人惊讶的——最难被战前作品训练出来的模型正确识别出来。由于所有这些书都被战后的图书馆员标记为科幻小说,我们不再对不同读者的选择实践进行对比。在发现科幻小说的读者之间有很大的共识之后,我们现在要对比不同时期作家实践中定义的科幻小说的不同版本。图3显示了该对比。把每一个箭头都看作是对视差的测量,这显示出当我们从战前的观测点转移到战后的观测点时,一本书的位置是如何变化的。
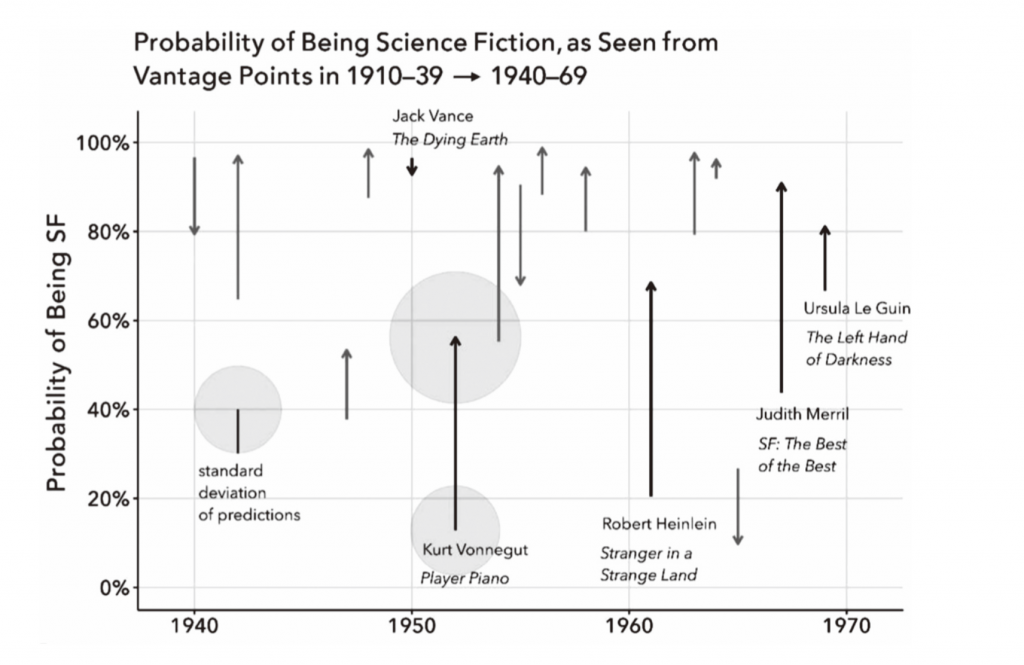
用两套不同的模型预测一卷书是科幻小说的概率。每个箭头的起点是用1910年至1939年样本进行训练的模型所感知到的概率;终点是根据1940年至1969年的例子训练的模型所感知到的概率。带标签的书是黑色的;那些没有标记的是灰色的。《自动钢琴》(Player Piano)的阴影圈的垂直半径代表了那本书预测的标准差;对其他书籍的预测也有类似的变化。
长长的向上的箭头表明一部作品与战前的科幻小说非常不同。这些作品中有许多都清晰地体现出文体类型的变化。朱迪思·梅里尔(Judith Merril)被誉为“1960年代科幻小说新浪潮最有名、最健谈的倡导者之一”,她编辑的选集对新趋势进行了戏剧化的呈现,这不无道理[50]。罗伯特·海因莱因(Robert Heinlein)的《异乡异客》(Stranger in a Strange Land)也因提出一些社会问题而著称,这些问题在《惊奇故事》中则是没有体现的。然而,杰克·万斯(Jack Vance)的流浪汉小说(picaresque novella)《垂死的地球》(The Dying Earth)如果从过去的视角来看,则更容易被视为科幻小说。
《垂死的地球》可能已经过时了,它是以一个程式化的遥远的未来为背景的,缺乏许多战后科幻小说中相对的社会现实主义。但在推测图3中的小箭头向下运动的原因之前,我们应该问一下它实际上传达了多少证据。每个箭头的起点和终点代表30次不同建模运行的平均值。每一次测试都使用了略微不同的书籍样本来模拟战前和战后对科幻小说的看法,并对每一卷科幻小说给出了不同的概率。《自动钢琴》的阴影圈代表了一本书的典型变化范围:大约68%的概率估计落在阴影圈的某个地方。即使是随便一瞥便能发现,相对于随机的变化,对《垂死的地球》的不同视角的平均差异是很小的。统计检验证实,战前和战后对杰克·万斯中篇小说看法的差异很可能是偶然发生的。图3所示的其他四个视差测量值都代表了具有统计学意义的变化。但是,视差的测量只是粗略的近似,并不能单独告诉我们某本书与之前的同类作品是怎样不同。为了解释这个证据,我们需要用更熟悉的批判性调查方式来补充它。
事实上,图3只是文学史研究者们经常尝试的思想实验的一个稍微系统化的版本。如果我们想要理解为什么简·奥斯丁的《爱玛》如此重要,我们可以想象自己置身于一个没有亨利·詹姆斯(Henry James)和乔治·艾略特的世界——这个世界最接近的比较对象是玛丽亚·埃奇沃思(Maria Edgeworth)。不同视角的模型不会取代那种想象的沉浸感,它们不像人类读者那么敏感。然而,它们确实有真正的无知优势。一个有博士学位的人很难忘记19世纪发生的事情,但是一个基于30年证据的模型只知道这30年。它不必假装失忆,这使它成为一个有价值的信息提供者——就好像是一位1815年或1935年的访客,我们可以观察到它对后来作品的反应。
如果我们想更全面地理解一个模型的反应,我们可以看它是如何阅读文本的。例如,我们不必去推测厄休拉·勒·奎恩(Ursula Le Guin)的《黑暗的左手》(The Left Hand of Darkness)[51]中可能延伸了战前科幻小说定义的哪些方面。我们可以将战前和战后的模型应用到书中的个别段落中,寻找它们不一致的地方。模型分歧最大的一段正巧在讨论这本书的中心前提:格森(Gethen)星球上的人在他们生命的不同时刻可以扮演不同的生育角色。战前的模型并不认为这是典型的科幻小说。下面我将最能引起意见分歧的词用加粗标出:
试想:任何人都可以做任何事。这听起来很简单(simple),但其心理影响(psychological effects)却是不可估量的。事实上,17岁到35岁左右的人(如尼姆所说)都有可能“被生育所束缚”,这意味着这里的女性在心理上或生理上(physically)都不会像其他地方的女性那样完全“被束缚”。负担(burden)和特权(privilege)被相当平等地分配(shared);每个人都有同样的风险或同样的选择(choice)。因此,这里没有人比其他地方的自由男性(free male anywhere)更自由(free)[52]。
“男性”这个词确实在此处使性成为了主题。但这只是这段文章标志着科幻小说类型转变的方式之一。更广泛地说,它的语言是由心理和社会推理(负担、特权、自由、选择、共享、心理影响)形成的。海因莱因的政治观点与奎恩的截然不同,但通过(借助模型)对《异乡异客》进行深入解读,我们可以发现,它以类似的方式改变了基于战前的科幻小说的模式:它讲述了一个基于心理和社会冲突而非解决物理问题的故事。
简而言之,定量证据在任何尺度上都是相关的——从一段话到一本书,再到跨越世纪的趋势。但它可能在不同的尺度上有不同程度的重要性。在段落的层面上,定量信号常常被噪声淹没。例如,上面粗体字是从一本较长的书中抽取的一个小样本,只是松散地说明问题,而没有统计意义。更重要的是,我们熟悉的阅读策略在这个层面上太强大了,不需要太多的帮助,读者已经知道奎恩从物理科学转向了社会科学。我从《黑暗的左手》中引用的段落,来自一个人类学家的“田野笔记”[53]。越过模型来阅读这一章的意义,不是真的要确认我们的关键直觉,而是要确认模型的有用性。
当我们回到更大范围的描述,更多令人惊讶的模式变得可见了。例如,海因莱因和奎恩的作品在很大程度上不同于传统的文体类型,这一点并不总是很明显。再进一步缩小,我们开始看到在普通阅读规模下看不见的模式。通过测量不同时期训练出来的模型之间的距离,我们发现科幻小说常常变化得很慢(比奇幻文学要慢)。上述对比,跨越1940年的分界线,发生在变化最迅速的时期。科幻小说在这一分水岭上的变化,比跨越发明这个词的1920年代的变化还大。这个结论并不是每个历史学家都能立即得到的,所以即使是远读者也需要在不同的尺度之间架起桥梁,以展示在特定时期对历史距离的抽象测量是如何与可见的文体创新联系在一起的。
以上所述的文体类型历史与公认的观点至少在两方面存在分歧。我淡化了《惊奇故事》所带来的转变,而强调了与现在所谓的奇幻文学相比,科学冒险故事和科幻小说具有长期的稳定性。但我并不是说,数字赋予了这些结论任何特殊的权威。统计模型只是证据的另一种形式,需要和其他所有证据一起权衡。这篇文章向文学学者推荐数字,并不是把它作为一种唯一可靠的证据形式,而是作为一种灵活的描述语言,尤其适合与视角和程度有关的历史性的问题。
在理论上,我们已经知道文体类型是偶然的、模糊的结构,但我们的描述性语汇仍然诱使我们划出清晰的界限。我们说哥特小说是一种文体类型(genre),或者仅仅是一种模式(mode),或者是在某一时刻成为一种模式的文体类型。我们说奇幻文学和科幻小说不同,或者不是不同,或者是在《指环王》(The Lord of the Rings)之后才与科幻小说完全不同。我称之为“视角建模”(perspectival modeling)的策略可以支持更灵活的描述方法,它从历史上的读者实践开始,并跟踪他们之间的关联程度。文学星丛(literary constellations)形成于不同时期的视角,相互认识,相互牵引。从这个过程中产生的地图可能仍然有一些熟悉的地标——例如,一个模糊的区域被标记为“科学传奇”,旁边是一个更模糊的区域,被重叠的标签为如“奇幻文学”和“超自然小说”。但这幅地图是一个连续统一体:历史学家可以用它来衡量争论的程度和变化的相对速度,而不是争论语义的界限。
四、计算阐释学
文学定量方法的批评者经常争论说,数字暗示着一种客观性,与约翰娜·德鲁克所称的“人文学科的相对主义和比较方法”[54]不相容。德鲁克最系统地推进了这个案例,她认为,我们与其他学科共享的定量方法使证据看起来“不言自明、价值中立、观察者置身事外”[55]。德鲁克并非个例,这种对数字的批评是如此普遍,以至于它可以被简化为一种轻蔑的姿态。例如,亚历山大·R.加洛韦(Alexander R. Galloway)顺便暗示过,“数豆子”的方法是为“不懂阐释学的年轻‘教授’”准备的[56]。
本文论证了定量方法可以很好地适用于比较的、相对主义的和阐释学的问题。数字本身并不能保证客观性,它们只是人类为了区分程度的不同而创造的符号。由于数字在自然科学中很快变得有用了,我们已经学会将它们与物理测量联系起来,而物理测量并不很大程度上依赖于观测者的位置。但它们的效用并不限于此。今天,即使是自然科学家也在使用统计数据来证实研究人员的主观假设或先验。人文主义者可以带头使用统计模型来代表处于历史位置的观察者相互冲突的观点。
计算的批评者警告研究人员不要把计算机当作客观的神谕,这是正确的。特别是无监督算法,它们被授予的权威往往比它们应得的多。用于聚类和主题建模的无监督算法不需要人工标记的示例,只要输入文本和模式就可以了。偶尔,研究人员会想象,由于缺乏直接的人类监督,这些结果具有特殊的权威性。艾伦·刘(Alan Liu)称这种幻觉为“白板解释”[57]。在现实中,即使是无监督的算法也是由人类设计的,人类会对期望发现的模式做出假设。
在理解这些假设的作者手中,无监督算法也有正当的用途。但这篇文章探索了一种不同的方法,以人类历史作为更明确的解释基础。监督机器学习很像人文主义者对待过去的传统方法,利用在另一个地方和时间产生的文件,重建一个已经消失的世界视角。监督模型和人们更熟悉的方法的主要区别在于,监督模型可以对新的证据做出预测——这种预测允许模型像一个活生生的观察者那样行事,并会犯一些能揭示问题的错误。通过研究这些错误,我们可以找出视角之间的视差,测量没有数字就很难表示的程度差异。
为了处理数字天生具有客观性这一普遍假设,我在这篇文章中花了大量精力来说明机器学习能够很好地回答棘手的视角问题。但我也使用了更熟悉的方法,从细读到反思爱德华时代的营销。既然不同的方法适用于不同的问题,当然也就没有正确的解读文学的方法。有时我们需要仔细审视《黑暗的左手》中的一段话,有时我们也需要比较跨越两个世纪的一系列模型。这篇文章并不是试图通过妥协来解决方法上的冲突,而是探索了各种不同的解释方案[58]。“选择越多越好”是我的隐含前提。
如果定量方法与人文主义者现有的解释理论没有冲突,那么为什么对这个问题的争论会如此激烈?我认为真正的问题是新方法仍然难以获得。因为文学专业的学生没有受过统计学方面的训练,所以他们不会把依赖于数字的方法看作是给他们的机会。相反,新方法对其他人来说似乎是一个机会——这种前景很少能给人类的心灵带来纯粹的快乐,即使研究人员能够使用一种学习算法,将记忆中的玛德琳蛋糕的味道折射成一道在每个观察者看来都不一样的彩虹,这种情况仍然存在。一种方法具备人文主义性质,不是当它具有正确的哲学品质的时候,而是当它实际上被人文主义者使用的时候。
当数字方法能够将新方法包装成用户友好的工具时,人文学科最容易接受这些方法。但是对于复杂的问题,一个用户友好的界面只能是一个诱导性的“毒品”。为了验证自己的结论,使用数字的文学学者需要统计学知识和一点编程经验。如果我们把这些科目纳入文学课程,我们的学科很快就会发现自己在以新的视角探索变化和连续性。如果我们不这样做,就没有什么论点足以使新方法流行起来,一个没有接受过使用统计模型训练的学科必然会将它们视为外来竞争对手。在这种情况下,类似本文所探讨的问题可能会由社会科学家来提出和回答。
—————————————————————————————————————————————————————————————
Machine Learning and Human Perspective
Ted Underwood
Abstract: Numbers are not only useful for measuring objective facts, but also for interpreting perspectival differences. Quantitative methods are well-suited to comparative, relativistic and hermeneutic questions, which is computational hermeneutics. A particular type of model constructed by quantitative statistics, using documents produced in another time and space, reconstructs a vanished perspective on the world, much closed to the humanist’s traditional approach to the past. The difference is that this supervised model can make predictions about new evidence — and it can make revealing mistakes, just as a living observer might. By studying those mistakes, we can map parallax between perspectives and measure differences of degree that would be hard to represent without numbers, which is the new opportunity machine learning brings to humanities research.
Keywords: Measurement of Literature; Perspectival Differences; Quantitative Methods; Machine Learning; Computational Hermeneutics
—————————————————————————————————————————————————————————–
编 辑 | 姜文涛
注释:
[1]特德·安德伍德(Ted Underwood)是伊利诺伊大学厄巴纳分校信息科学学院和英语系教授。他出版了三本书,最近出版的是Distant Horizons: Digital Evidence and Literary Change, University of Chicago Press, 2019。Ted Underwood,“Machine Learning and Human Perspective,”PMLA, Vol.135, No.1, 2020, Published by the Modern Language Association of America. Translated and Published in Chinese with author’s permission.
[2]Rachel Sagner Buurma, Laura Heffernan,“Search and Replace: Josephine Miles and the Origins of Distant Reading,”Modernism/ Modernity, April 11, 2018, https://modernismmodernity.org/forums/posts/ search-and-replace.
[3]Wilhelm Dilthey, The Formation of the Historical World in the Human Sciences, Princeton University Press, 2002, pp.154-164.
[4]Stanley Fish“, What Is Stylistics and Why Are They Saying Such Terrible Things about It?,”in Seymour Chatman ed., Approaches to Poetics, Columbia University Press, 1973, pp. 109-152.
[5]John K. Smith,“Quantitative versus Interpretive: The Problem of Conducting Social Inquiry,”New Directions for Program Evaluation, no. 19, 1983, pp. 27-51.
[6]Franco Moretti, Graphs, Maps, Trees: Abstract Models for Literary History, Verso, 2005, p. 91.
[7]Johanna Drucker“, Why Distant Reading Isn’t,”PMLA, vol. 132, no. 3, May 2017, p. 634.
[8]Richard Jean So“, All Models Are Wrong,”PMLA, vol. 132, no. 3, May 2017, pp. 668-673; Andrew Piper, “Think Small: On Literary Modeling,”PMLA, vol. 132, no. 3, May 2017, pp. 651-658.
[9]关于“界限”在这种研究文化的方式中的重要性,见Andrew Abbott,“Things of Boundaries,”Social Research, vol. 62, no. 4, 1995, pp. 857-882。
[10]See Judith Butler, Gender Trouble: Feminism and the Subversion of Identity, Routledge, 1990.
[11]Linda Martín Alcoff, Visible Identities, Oxford University Press, 2006, p. 148.
[12]Ted Underwood et al.,“The Transformation of Gender in English Language Fiction,”Cultural Analytics, February 13, 2018, http://culturalanalytics.org/2018/02/the-transformation-of-gender-in-english-language- fiction/.
[13]See George Eliot, The Mill on the Floss, 3 vols., William Blackwood, 1860.
[14]原文使用斜体字标注,为适应中文阅读,标注方式改为加粗。——译注
[15]George Eliot, The Mill on the Floss, 3 vols., vol. 1, pp. 45-46.(中译本:乔治·艾略特:《弗洛斯河上的磨坊》,祝庆英、郑淑贞、方乐颜译,上海:上海译文出版社,2008年,第24页。——译注)
[16]Ted Underwood et al.,“Replication Data for‘The Transformation of Gender’,”Harvard Dataverse, 2018, https://doi.org/10.7910/DVN/ZM2MAN.
[17]我用对数刻度来让这个对角线上的分歧更明显;如果我用的是普通的标尺,对角线就会因为性别的一致而缩小。
[18]Ted Dunning,“Accurate Methods for the Statistics of Surprise and Coincidence,”Computational Linguistics, vol. 19, no. 1, 1993, pp. 61-74.
[19]Ceorge Eliot, The Mill on the Floss, 3 vols., vol. 3, p. 231.(中译本第438页。强调标记为本文作者添加。——译注)
[20]Ted Underwood et al.,“The Transformation of Gender in English Language Fiction,”Cultural Analytics, February 13, 2018, https://culturalanalytics.org/2018/02/the-transformation-of-gender-in-english- language-fiction/.
[21]See Underwood et al.“, The Transformation of Gender in English Language Fiction.”
[22]Miriam Posner“, What’s Next: The Radical, Unrealized Potential of Digital Humanities,”Miriam Posner, July 27, 2015, https://miriamposner.com/blog/whats-next-the-radical-unrealized-potential-of-digital- humanities/.
[23]Darko Suvin, Metamorphoses of Science Fiction: On the Poetics and History of a Literary Genre, Gerry Canavan ed., Peter Lang, 2016, p. 79.
[24]Robyn Warhol“, Genre Regenerated,”in Warhol ed., Introduction. The Work of Genre: Selected Essays from the English Institute, English Institute/American Council of Learned Societies, 2011, https://hdl.handle. net/2027/ heb .90055.0001.001.
[25]Ralph Cohen“, History and Genre,”New Literary History, vol. 17, no. 2, 1986, p. 210.
[26]See Brian Stableford, Scientific Romance in Britain, 1890–1950, Fourth Estate, 1985; Gary Westfahl, Mechanics of Wonder: The Creation of the Idea of Science Fiction, Liverpool University Press, 1999.
[27]Mark Bould, Sherryl Vint, The Routledge Concise History of Science Fiction, Routledge, 2011, p. 1.
[28]Arthur C. Clarke, Profiles of the Future: An Inquiry into the Limits of the Possible, Rev. ed., Harper and Row, 1973, 21n1.
[29]这些模型是使用scikit-learn的正则化逻辑回归创建的(Pedregosa et al.“, Scikit- learn: Machine Learning in Python,”JMLR, vol. 12, 2011, pp. 2825-2830)。这些特征包括最常见的单词和标点符号,以及一些文体特征,比如句子长度;数据来源于Boris Capitanu et al.,“The HathiTrust Research Center Extracted Feature Dataset 1.0,”HathiTrust Research Center, 2016, https://doi.org/10.13012/J8X63JT3。通过网格搜索选择每个模型的特征个数,即正则化常数。可视化使用ggplot2生成(Hadley Wickham, Ggplot2: Elegant Graphics for Data Analysis, Springer, 2009)。更多细节请参见Ted Underwood,“Code and Data to Support‘A Measured Perspective,’”Zenodo, April 1, 2018, https://doi.org/10.5281/zenodo.1210966。
[30]Sarah Allison et al.,“Quantitative Formalism: An Experiment,”Stanford Literary Lab, January 15, 2011, https://litlab.stanford.edu/LiteraryLabPamphlet1.pdf; Ted Underwood, Distant Horizons: Digital Evidence and Literary Change, University of Chicago Press, 2019, pp. 34-67.
[31]将奇幻文学和科幻小说进行比较的想法来自艾伦·刘(Alan Liu)。
[32]在稍后阶段的调查,有必要区分国家传统,但儒勒·凡尔纳的作品和卡雷尔·恰佩克(Karel Čapek) 的科幻小说非常易读,即使是被翻译过的。我还规范了英式和美式拼写,以便提出跨越大西洋的问题。儿童文学被排除在这一分析之外,因为它与奇幻文学的紧密联系提出了需要更长时间来研究的问题。
[33]See Catalogue of the Principal English Books in Circulation at Mudie’s Select Library, Mudie’s Select Library, 1911.
[34]José Calvo Tello,“Genre Classification in Spanish Novels: A Hard Task for Humans and Machines?,” European Association for Digital Humanities, Galway, December 2018. EADH 2018, https://eadh2018. exordo.com/files/papers/46/final_draft/20181205_genre_classification_human_vs_machines.pdf.
[35]Mark Bould, Sherryl Vint, The Routledge Concise History of Science Fiction, Routledge, 2011, p. 1.
[36]Gary Westfahl, Mechanics of Wonder: The Creation of the Idea of Science Fiction, Liverpool University Press, 1999, p. 12.
[37]Gary K. Wolfe, Evaporating Genres: Essays on Fantastic Literature, Wesleyan University Press, 2011, p. 21.
[38]See Gary K. Wolfe, Evaporating Genres: Essays on Fantastic Literature.
[39]Gary K. Wolfe, Evaporating Genres: Essays on Fantastic Literature, p. 164.
[40]Gary K. Wolfe, Evaporating Genres: Essays on Fantastic Literature, p. viii.
[41]See Dorothy Scarborough, The Supernatural in Modern English Fiction, G. P. Putnam, 1917.
[42]指英国国王爱德华七世统治时期,1902年至1910年。——译注
[43]Catalogue of the Principal English Books in Circulation at Mudie’s Select Library, Mudie’s Select Library, 1911, pp.886-888.
[44]John Rieder“, On Defining SF, or Not: Genre Theory, SF, and History,”Science Fiction Studies, vol. 37, no. 2, July 2010, pp. 191-192.
[45]Franco Moretti, Graphs, Maps, Trees: Abstract Models for Literary History, Verso, 2005, p. 21.
[46]Catalogue of the Principal English Books in Circulation at Mudie’s Select Library, Mudie’s Select Library, 1911, p. 886.
[47]See James O. Bailey, Scientific Fiction in English, 1817–1914: A Study in Trends and Forms, PhD dissertation, University of North Carolina 1934 .
[48]David Richter, The Progress of Romance: Literary Historiography and the Gothic Novel, Ohio State University Press, 1996, pp. 161-162.
[49]为了简单起见,我通过测量在一组作品上训练的模型试图识别定义另一组作品的边界时所失去的准确性,来衡量流派之间的距离(以及后来的流派内的变化速度)。有更精确的方法来比较模型。我还假设模型A到模型B的距离等于模型B到模型A的距离,来使其简化。这些简化并没有明显地扭曲这里报告的结论,但他们确实淡化了文化的非欧几里得几何。在没有欧几里得假设的情况下,为了更精确地测量模型之间的差异,参见Ted Underwood“, The Historical Significance of Textual Distances, ”Proceedings of the Second Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, August 2018, pp. 60-69. ACL Anthology, https://aclweb.org/anthology/W18-4507。
[50]Rob Latham,“Sextrapolation in New Wave Science Fiction,”Science Fiction Studies, vol. 33, no. 2, July 2006, p. 251.
[51]See Ursula Le Guin, The Left Hand of Darkness, Ace, 1986.
[52]Ursula, The Left Hand of Darkness, pp. 93-94.
[53]Ursula, The Left Hand of Darkness, p. 89.
[54]Johanna Drucker,“Humanistic Theory and Digital Scholarship,”in Matthew K. Gold ed., Debates in the Digital Humanities, University of Minnesota Press, 2012, https://dhdebates.gc.cuny.edu/debates/text/34.
[55]Johanna Drucker“, Humanities Approaches to Graphical Display,”Digital Humanities Quarterly, vol. 5, no. 1, 2011, https:// www.digitalhumanities.org/dhq/vol/5/1/000091/000091.html.
[56]Alexander R. Galloway,“Everything Is Computational,”Los Angeles Review of Books, June 27, 2013, https://lareviewofbooks.org/article/franco-morettis-distant-reading-a-symposium/.
[57]Alan Liu“, The Meaning of the Digital Humanities,”PMLA, vol. 128, no. 2, March 2013, p. 414.
[58]文学学者使用数字的方式比一篇文章所能探究的更广泛。关于代表地理的模型(Elizabeth F. Evans, Matthew Wilkens,“Nation, Ethnicity, and the Geography of British Fiction,”Journal of Cultural Analytics, July 13, 2018, https://culturalanalytics.org/2018/07/nation-ethnicity-and-the-geography-of- british-fiction-1880-1940/)或跨越语言边界的模型(Hoyt Long, Richard Jean So,“Turbulent Flow: A Computational Model of World Literature,”Modern Language Quarterly, vol. 77, no. 3, September 2016, pp. 345-367),我没有讲太多。我也没有完全探究那些将使用数字的学者们分成两派的方法论争论(Katherine Bode,“The Equivalence of‘Close’and‘Distant’Reading; or, Toward a New Object for DataRich Literary History,”Modern Language Quarterly, vol. 78, no. 1, 2016, pp. 77-106; Andrew Goldstone, “The Doxa of Reading,”PMLA, vol. 132, no. 3, May 2017, pp. 636-642;Lauren F. Klein,“Distant Reading after Moretti,”Arcade, 2019, https://arcade.stanford.edu/blogs/distant-reading-after-moretti;Dennis Yi Tenen,“Toward a Computational Archaeology of Fictional Space,”New Literary History, vol. 49, no. 1, 2018, pp. 119-147)。无可否认的是,我已经暗示了对这些争论的一般性回应,即不同的方法通常是兼容的。语料库可以比较,分析的尺度可以相互联系。
原刊《数字人文》2020年第3期,转载请联系授权。