中国数字人文 Digital Humanities in China ![]()
![]()
![]()

种族与远读
作者:埃德温·罗兰 ;转自:公号 DH数字人文
概念与实践

苏真 / 加拿大麦吉尔大学英语和文化分析系
埃德温·罗兰 / 加州大学圣巴巴拉分校英语专业
尹倩(译) / 上海大学中文系
陈大龙(校) / 浙江大学国际联合学院
————————————
摘要:随着数字技术在人文研究领域的渗透与应用,由弗兰克·莫雷蒂提出的“远读”方法对文本分析具有启发意义。采用远读和文本细读相结合的方式,旨在将远读和种族批判这两种尚未完全结合的文化-文学分析方法进行关联,并发展出一套适合于分析文学中的种族和种族话语的远读批判范式。但是,一方面将措辞和句法等与种族联系在一起,易造成刻板印象;另一方面目前仍存在许多数字语料库和工具无法记录种族差异的方式。为突破此局限性,研究主要分为以下三个部分:一是聚焦战后美国小说,构建黑人/白人作者小说语料库,搭建模型以分析语料库中小说的整体文本特征,形成专业语词库;二是从分析和模型批判视角出发,主要观察计算机如何“理解”二进制(白人/黑人)框架中的种族差异;三是采用文本细读的方式探究小说《乔凡尼的房间》,最终揭示原本隐形的语言效果,暴露了白人性的变异或取代。最后,通过设想一种自反的方法,使计算机能够识别出被人们忽略的内容,同时也能提供新的观点和研究契机。
关键词:种族 远读 文本细读 文学风格 身份认同 模型批判
————————————
主持人按语:
用定量和计算的方法研究文学,在一二十年前刚刚出现的时候,是充满争议并常常被拒斥的。但是,在最近五年,这种方式越来越成为主流而被接受。像特德·安德伍德(Ted Underwood)、安德鲁·派珀(Andrew Piper)和凯瑟琳·博德(Katherine Bode)等学者已经使用计算方法,特别是机器学习,研究了文学类型的历史、小说与非虚拟文学的区别等主题。
但是,学者们在使用这些方法研究社会身份,特别是种族与文学之间的问题方面进展比较缓慢。在北美的语境中,原因并不难理解,比如,美国有漫长且丑恶的使用科学的方法来贬低和压迫少数种族群体(比如非裔美国人)的历史。统计学中很多最基本的方法,比如主成分分析的发明,部分目的就是用来证明黑人天生就是智力低下的。在很多方面,对种族与文学这一问题的研究,特别是关于种族的批评性研究,都对理解种族和种族差异的定量方法和类型进行了批评和颠覆,并将其作为研究的前提。因此,很长时间以来,在研究北美的种族和文化方面的学者都回避或者质疑量化研究。
种族研究学者对量化研究的主要批评是,这种方法把种族“具体化”(reify)了,也就是说,把种族身份的丰富性和复杂性转变成了简单的二元分类(比如“白人”与“黑人”的分类),进而消除了作为白人或黑人的真正意义。而且这些分类常常被用于压迫少数种族群体。而苏真和罗兰论证了,机器学习的新路径使我们得以用更灵活也更稳健的方法来研究种族和文学这一问题。这响应了安德伍德在《机器学习与人文视角》[1]中所作的论证。
在本文中,苏真和罗兰展示了机器学习的批判性方法如何避免这种具体化的过程。实际上,一个自反性的机器学习路径可以有助于解构种族的分类,展示出这些分类内在的不一致性或偶然性,进而把种族作为在文学中的社会建构来研究其历史起源和演化。
这篇文章虽然聚焦于美国语境下的种族,但是应该能引起更广泛的兴趣,如果学者们希望使用定量或计算方法研究文学中的社会身份问题,而避免将社会身份的丰富性具体化为简单的二元分类(比如男性与女性、本国人与外国人、华裔与非华裔等)的话。总的来说,这篇文章试图通过研究社会身份这个在人文和文学研究中往往回避定量方法的难题,来推进数字人文的发展。
(苏真)
引 言
本文旨在将远读和种族批判这两种尚未完全结合的文化-文学分析(cultural- literary analysis)方法联系在一起。其中,“远读”(Distant Reading)是弗兰克·莫雷蒂(Franco Moretti)提出的一个概念,是指使用定量方法研究大型数字化文本语料库。这项研究的主要目的是在数以千计的文本规模上对文本模式的内容和形式进行识别,而这是人眼(文本细读)做不到的。当然,用数字技术对文学文本进行分析并非新鲜事。我们甚至可以追溯到更早的文学评论家和历史学家,他们借助数字技术和统计数据来研究文学风格和文学历史。这些研究学者包括社会经济史年鉴学派图书历史学家、诗人兼评论家约瑟芬·迈尔斯(Josephine Miles)、文化社会学家詹尼斯·莱德威(Janice Radway)和文学学者约翰·伯罗斯(John F. Burrows)。另外,2013年莫雷蒂《远读》(Distant Reading)一书的出版全面激发了人们使用计算机和统计学知识来进行文学研究的兴趣。在这项研究中,莫雷蒂将距离定义为“知识的条件:其允许研究者专注于比文本小得多或大得多的单位:比如装置、主题、比喻,或者流派和系统。如果说在这无限小和无限大之间,文本自身已然消失,那么这就是一种人们可以很明确地表示‘少即是多’的情况。如果我们完全理解这个系统,就必须接受这样做会失去一些内容”。[2]此后,许多学者,诸如娜塔莉·休斯顿[3]和坦尼娅·克莱门特[4]等,在19世纪英国诗歌和英美文学现代主义等领域对这一研究范式进行了进一步拓展和探讨。
这项研究的大部分实践,特别是斯坦福大学文学实验室的研究,主要集中在对纯文学问题的探讨上。例如,实验室最近发布的一本小册子就使用了远读的方法来探究“句子层的风格”(Allison etc.)。[5]安德鲁·派珀(Andrew Piper)[6]和伊娃·波特兰斯(Eva Portelance)等学者则将远读方法推向了对文化资本问题的研究,明确了文学领域的权力动态,例如什么类型的书能获得文学奖(Piper 和Portelance)。但在很大程度上,(那些追随莫雷蒂脚步和莫雷蒂本人的)学者们都避免使用大规模的量化方法来探讨身份问题,特别是种族身份和少数族裔话语问题。造成这种情况的原因并不难理解,远读需要量化,因此,采取远读方式分析种族问题需要对种族身份或种族化语言进行量化。人们只要引用诸如“钟形曲线”(bell curve)或“优生学”(eugenics)之类的术语,即可联想起使用表面看来客观的量化方法来贬低有色人种的漫长而丑陋的历史,更广泛地说,用那种方法授权和加强种族分层的历史。相比之下,文化和历史的研究方法强调种族的社会建构性,种族这个范畴回避量化或者使量化方式站不住脚。
塔蕊·麦克弗森(Tara McPherson)和金·加伦(Kim Gallon)等学者对“数字技术”如何潜在地对种族偏见进行编码表示了特别关注。麦克弗森提醒我们,种族差异与1960年代和1970年代产生的现代计算机技术创新的历史息息相关。当代数据挖掘方法,例如数字人文领域中越来越常见的自然语言处理方法,正是这场技术革命的产物,也就必须承受种族歧视之重,因为这正是种族歧视的部分影响(McPherson)[7]。加仑还指出了不加批判地使用这些方法的危险。她呼吁构建“黑人数字人文科学”(black digital humanities),将计算方法用于文化或历史研究,任何实践的开端都以计算的种族批判为前提[8]。
通过一个简单的应用问题即可说明将数据科学应用于种族和文学研究可能性是荒谬的。如果我们给你一小段小说文本,只告诉你这段文字是一位美国作家写的,出版时间介于1950年到2000年,那么你能猜出作者的种族身份吗?
仅仅通过这个问题,我们就窥见了这种应用多么荒谬,可能多么无礼。任何将措辞和句法,或风格和叙事,与种族联系在一起的尝试,最终很可能会重现刻板印象。黑人作者只写X或Y,而白人作家写A或B。这些主张植根于对身份的简约性的和种族主义的假设。此外,整个实践过程是建立在错误的假设基础上的。例如,“种族身份”(racial identity)在一定程度上具有表演性,其在语言中的表达方式取决于具体的情境;一个单词的使用,如“黑人”(Negro),对于不同的作者来说,在不同的情境中也会产生不同的意义,即使作者都是非裔美国人或黑人(black)。而且,并不是所有的黑人小说家都进行“黑人”文学(“black” literature)创作。有人可能会争辩说,是“黑人”文学这一类别的区分太不合逻辑了,以至于不可行。然而,在线广告商恰恰是这样使用分类算法来理解我们的种族身份与我们如何使用词语两者之间的关系的。
将远读和种族研究结合起来所面临的挑战是显而易见的。除了麦克弗森和加仑外,诸如劳伦·克莱恩(Lauren F. Klein)[9]和罗皮卡·里萨姆(Roopika Risam)[10]等数字人文研究者还准确地记录了许多现有数字语料库和工具无法记录的种族差异的方式。在本文中,我们对这项研究进行了拓展,以开发一个更具包容性的远读模式,此模式对能使其从远距离看待事物的权力形式进行了反思。继克莱恩之后,我们不仅要研究远读所揭示的问题,也要探索其隐藏的内容。具体而言,我们构建了一种远读的批判模式,它将对种族和计算的批判整合到整个研究设计中,同时还产生了对文学批评写作有潜在益处的结果。首先,我们从简单的计算方法开始,引入一种常见的远读模式;然后,通过批判的方式对构建的模型提出质疑并调整转换,以达成两个目的:一是阐明用于种族分析的标准计算方法的局限性;二是根据标准计算产生的结果,进一步增进对所研究文本和作者的理解。我们认为,对远读的辩证分析视角(批判和计算之间的相互作用)使得对种族问题的量化研究成为可能,而不仅仅是重新阐释种族分层。事实上,揭露计算存在的种族局限性可以揭示文学史中原本被遮蔽的内容。
一、数据与方法
计算方法能否帮助我们研究已被正式认定为“文学”(比如小说)的文本制品(textual artifacts)中的种族话语?为了回应这个问题,首先,我们需要构建一个与种族规范性区别相对应的文本语料库。我们决定主要研究战后的美国小说,并构建语料库,此语料库的文本资源包括被平均分配的黑人作者和白人作者所创作的小说。以期通过研究包括这两种文本资源在内的语料库之间的相似性和差异性,来理解不同种族身份的作者所写小说之间的区别。
其中,黑人作者小说语料库的构建过程如下:一批任职于堪萨斯大学的学者和图书管理员,在玛丽玛·格雷厄姆(MaryemmaGraham)的指导下,参与了黑人写作历史项目(Projecton the History of Black Writing)的相关研究工作。他们花了20年时间来识别和获取被认为是黑人或自称是黑人的作家写作的每一部小说的纸质副本。这批学者和图书馆员总共发现了大约1,200本这样的小说,这些小说于1880年至2000年之间出版。在芝加哥大学同事的帮助下,到目前为止,他们已经对220部这样的小说进行了数字化处理,这些小说代表了整个语料库的随机样本。然后,我们与一个团队的研究助理合作,确定了语料库中每位作者的性别。当然,这项研究的标准是很严格的:要按性别对作者进行标记,我们必须找到可靠的学术来源,以确定作者的性别或作者自己识别其性别的依据。如果找不到符合这一标准的证据,则对其不加标记,并将该作者置于语料库之外。这220部作品包括一系列经典文本和非经典文本,例如作为经典文本的托妮·莫里森(Toni Morrison)的《宠儿》(Beloved)和非经典文本的梅尔文·范比波斯(Melvin Van Peebles)的《真正的美国人》(True American)。虽然我们相信堪萨斯大学的学者已经很好地阐释了黑人文学,但我们必须承认并强调,这一文学范畴的划分是一个颇具争议的类别,而我们的语料库也只是提供了其中的一个版本。
而为了构建白人作者的小说语料库,我们首先根据馆藏书目数据库WorldCat的记录,确定了1950年至2000年在美国大多数图书馆馆藏的两万部美国小说。其次,我们获取了其中大约9,000部小说的电子文本。然后,使用与上文中相同的方法和标准,与研究助理团队一起确定了小说列表上每位作者的性别和种族,这使得小说列表减少至大约5,900部。随后,我们对每一部小说的体裁(genre)进行核实,比如纯文学小说(literary fiction)或侦探小说(detective novel)。其中确定文本体裁的标准同样也很严格,如果小说的体裁没有明确,我们会联系一位学者专门去核实。而这也使得小说列表进一步减少,大约只有1,000部小说。最后,从语料库中最具代表性的体裁中分别随机抽取55部小说,包括畅销书、获奖小说、科幻小说和侦探小说。并将这个语料库的规模控制在220部小说,因为计算方法要求我们所比较的语料库在大小规模方面相同,而我们目前正好有220部黑人作者的数字化了的小说文本[11]。
我们将语料库限制在1950年到2000年之间出版的小说,因为这个时间段足够长,可以识别时间维度上的动向变化;也足够短,可以避免特定的种族化词语意义发生大的变化,比如“有色人种”(colored)或“黑人”(Negro)。继马修·雅各布森[12]和内尔·佩因特[13]等历史学家之后,我们认为在美国历史上的这一时期,种族以一种相对客观的方式通过语言被讨论、呈现。我们将白人作者的小说语料库按照体裁进行了细分,以判定我们在白人作者语料库和黑人作者语料库之间可能发现的任何差异是否源于体裁而不是种族。正如埃里克·洛特(Eric Lott)等文化历史学者所言,白人作者在不同的文学体裁中的表现也不尽相同。最后,我们确定了两个语料库中每一作者的性别,以明确性别是否是影响白人作者或黑人作者在小说写作中表达方式差异的重要因素。
虽然我们确定作者的种族身份是白人还是黑人的过程是基于对每一位作者的学术研究,但这个过程仍然有将种族身份具体化为一个范畴的风险。作者的种族本体(racial ontology)并不稳定,白种人或黑种人的意义随着时间和地点的变化而发生变化。例如,如今大多数学者认为混血作家内拉·拉森(Nella Larsen)是黑人。但这种分类自1920年代以来一直在变化,在拉森写作的历史时期,她通常被称为“穆拉塔”[14]。与此同时,给作者贴上白人或黑人的标签可能会遮蔽掉交叉性所具有的活力。像詹姆斯·鲍德温(James Baldwin)这样的小说家在我们的语料库中被贴上了黑人的标签,但鲍德温将自己定位为同性恋者和作家。人不能只有一个身份认同形式,而没有其它身份认同形式。我们在文章的最后部分重新审视了这些问题,在那部分的论述中,我们再考虑种族化的作者身份的本体论问题的复杂性,而在这里我们只是暂时将这种身份视为固定的。
接下来,我们需要一种方法或“模型”对已构建的两个语料库进行分析。对于首次分析,我们将采用分类算法(classification algorithm)[15]。算法分类的目的是在给定文本可能属于的两个类别的情况下预测该文本的类别。例如,我们的电子邮件账户每天都会将“真正的”电子邮件和“垃圾邮件”区分开来,拦截收件箱中识别为垃圾邮件的邮件。为了学习如何做出这种区分,我们向一台计算机输入了数以万计真正的电子邮件和垃圾邮件的示例。该计算机将研究这两种文本类别的文本特征,关注哪些文本特征在其中一类文本中往往比在另一类文本中出现得更多。当然,这包括措辞(垃圾邮件更常使用类似“伟哥”这样的词)、语法(垃圾邮件更常使用不正确的语法)以及第一人称和第二人称的使用(垃圾邮件倾向于使用第二人称)等。然后,计算机将量化这些倾向——例如,垃圾邮件使用“伟哥”这个词的次数是真正电子邮件的十倍。这些倾向(具有定量权重的特征列表)成为计算机的“思维目录”(mental catalogue),使其能够区分两个电子邮件的类别。在科学术语中,我们将其称为“语言模型”(language model)。最后,计算机将测试该模型在执行分类方面的性能。我们会给这台计算机100封新的、未加标签的电子邮件,并要求其根据其“思维目录”预测这些电子邮件是真正的邮件还是垃圾邮件。如果它正确地预测了所给电子邮件的类别,比如正确率达95%,我们就可以判断语言模型总体上是准确的,模型是合理的。如果正确率低于这个阈值,计算机就会通过调整权重、删除特征的方式改进其目录并再次运行算法,以实现自我更新,直到其性能达到或高于所要求的阈值。
读完对这一算法的描述,人们很可能会从人文研究的立场提出一些直接的反对意见。我们能想到的一个主要的反对意见可能是,垃圾电子邮件和非垃圾电子邮件之间的区别并不等同于白人作者写作的小说和黑人作者写作的小说之间的区别。垃圾邮件和非垃圾邮件是对分别定义对象(电子邮件)的技术描述,白人作者和黑人作者是社会建构的种族身份类别。这种计算机分类方法并不适合文学批评,计算机分类的目标是识别和标记对象。少数群体话语分析的结合点在一定程度上是对范畴概念的批判和质疑。此外,我们还可以在此基础上再提出两个问题:第一,计算机为每个类别分配文本特征,在区分种族类别的情况下,这只是实现了种族身份的具体化,比如“黑人性”(blackness);第二,计算机依赖于这样的假设,即它的初始类别是一致的和真实的,它们二进制关系中是有意义的,但学者们长期以来一直认为,种族研究与二进制分类(binary classification)并不兼容。我们现在并不去否定这些反对意见,随着本文的展开,我们会改变我们所构建的模型,并在某些情况下重建模型以应对这些挑战。具体而言,为使主要的研究方法合理化,我们将提出两个论点。一方面,计算机的思维是关系型的,而不是本体论的。它不会为对象或文本的类别赋予本质属性,只是简单地标记以划分这些类别的界线,以及标记出界线的强弱。另一方面,虽然计算机必须从名义类别(nominal categories)开始工作,但其本身固有的方法是测试这些初始类别的完整性,并探索其潜在的偶然性或细微性。不过,现在我们先采用这种天真的方法,首先通过分类的方式,对其不可避免的局限性进行分析,并生成关于数据中的模式的初始信号,而后我们再对其进行修改和扩展。
因此,我们构建了一个模型,并相信这个模型总结了语料库中小说的整体文本特征。虽然此模型不能捕捉到每一个文本的特殊性,但它可以支持我们大规模地比较分析文本。该模型共包括三种特征:措辞(diction)、句法(syntax)和叙述(narrative)[16]。首先,我们让模型计算特定单词在文本中出现的频率。当然,词频不能捕捉到比喻(metaphor)或讽刺(irony)之类的意义,但它提供了一种窥见小说内容的方式。其次,通过模型计算不同词性(比如名词和副词)在文本中出现的频率。在这个部分,仅仅测量词语出现的频率也只能提供有限的信息,然而,虽然这些信息不能揭示文本段落层的句法意义,但它可以为我们揭示文本句子层的句法习惯。为此,我们计算了小说文本中某些“二元分词”(bigrams),即成对词类(parts of speech,如名词后接副词)在小说中出现的频率。最后,通过模型计算统计与文本所描述的故事世界相关的数据。其中包括对话与叙述的比例、小说中人物的数量、每个人物对叙述关注的均值,小说中手工制品与自然物品的比例,以及小说中的地点或背景的均值。我们把这第三类特征称之为“叙述”。虽然此模型对这些叙事特征的分析远不能完全捕捉到文学理论研究学者所主张的相关叙事概念的全部复杂性,也还很粗糙,但它有助于理解小说如何运用这些叙事的基本要素——对话、人物、物品和背景。
既然我们已经有了描述语料库中文本的语言模型,就可以使用该模型来尝试区分白人作者的小说和黑人作者的小说(如表1所示)。其中有些特征比较突出,首先,计算机在区分白人作者和黑人作者的小说方面表现十分突出,数值92%是一个非常高的准确率。虽然我们的特征列表相对简单,人们所期望的可能更为复杂,但是计算机不需要更多细微差别的特征就能完成这项工作,这体现了两类文本的区别。其次,文本体裁对区分白人作者的小说和黑人作者的小说影响不大。一位白人作者无论写的是畅销书还是科幻小说,都不影响他的作品与黑人作者写的小说区别的大小。
此外,计算机可以报告哪些特征对文本分类最为重要。除了句法特征和叙述特征外,从某种意义上来说,每个词语都可以视为一个特征。在可能对该模型有重大贡献的数百万个潜在特征中,实际上只有少数几个特征真正起作用(如表2所示)[17]。一种情形的轮廓随即浮现出来:黑人作者的小说往往比白人作者的小说使用更多的动词和名词(即动作和基于对象的语言)。与前者相比,后者倾向于使用更多的限定语言(比如“巨大的”[enormous]和“有趣的”[interesting])。而第二种看法有点儿薄弱,因为总体而言,白人作者的小说所使用的副词和形容词没有黑人作者的小说所使用的多,不过,白人作者小说的某些子集(如获奖小说)确实比黑人作者的小说包含更多的修饰语。在任何情况下,我们都发现关于语义和句法区别的信号。同时,我们也发现叙事方面的特征并不显著。
表1

表2

二、分析与模型批判
将这些结果作为更广泛分析的基础是很有吸引力的。例如,我们可能会发展出一种解读方式,认为文学上的“白人性”(whiteness)在某种程度上是由对语言限定(linguistic qualification,即意义的不断推迟)的关注来定义的。或者我们可以宣称,文学上的“黑人性”(blackness)体现在对事物和动作的注重超过对描述的注重,而且如果它确实描述了事物,那么这些事物往往会被种族化(“白的”[white]、“有色的”[colored])。或者把这些阅读资料结合起来,我们可能会认为白人作者和黑人作者所叙述的世界是截然不同的,他们倾向使用的词语定义了其不同的关注点,也聚焦于不同的担忧。区别明显的特征列表可以作为对他们所代表的语料库进行讨论的基础。
但是,采取这些行为中的任何一个都意味着我们接受了计算机的结果,更广泛地说,接受它的方法是有效的。或许我们并没有,或许我们最初的担忧仍然过于沉重。在这个部分,我们通过研究计算机本身的逻辑直接处理这些问题。我们首先关注的是,计算机如何“理解”二进制(白人/黑人)框架中的种族差异。然而,像加里·奥基希洛(Gary Okihiro)[18]这样的学者长期以来一直认为,种族研究往往超越或抵制二进制分类,白人和黑人并不是令人信服的、牢不可破的身份类别,而我们的计算机处理起来就必须加以区分。
然而,我们可以通过这些结果对这些显然是可靠的类别进行分解。关键是要考虑每个类别是如何表示其特征的,以及不同类别的表示方式有何不同。计算机的运作依赖于白人或黑人小说作者写作的文本所持有的一组特征,以便以92%的比率将一组特征与另一组特征区别开来。我们将其称之为“白人”特征和“黑人”特征。如果我们的主要作者身份类别实际上是完全相反的可公度的、整体的实体,那么他们也应该以可公度的方式表示这些特征。例如,黑人作者的小说应该把白人和黑人的特征作为一个范畴一致地表示出来。但是如果并非如此,我们称之为黑人作者的小说可能只是许多较小的分类的集合。这一类别可能是由差异中的差异构成,因此它可能不具有与我们的另一个类别的可公度性。
其中,通过一个类比将有助于解释计算机如何处理文本组之间的相互关系。设想存在两间教室,每间教室有十名学生。如果我们想知道两间教室的学生是否都长得比较高(因为我们想知道A教室的课桌高度是否适合B教室的学生),那么我们可以询问每个班级学生的平均身高是多少,然后对这两个平均值进行比较。现在假设这两个班级的平均身高都是5英尺6英寸。如果两间教室学生的身高都接近这个高度,那么平均身高会显示A教室的课桌高度同样也适合B教室的学生。现在设想第二种情况,A教室和以前一样,但把B教室平均分配给5英尺高和6英尺高的学生。同样,在这两个教室里,平均身高都是5英尺6英寸,然而在这种情况下,B教室的学生都无法正常坐在A教室的课桌前。这两种情况表明,平均身高的统计数据并非毫无意义,而是具有潜在的欺骗性。幸运的是,我们可以通过第二个统计特征值来评估平均值的有用性:即方差(variance)。在第一种情况下,由于大多数学生的身高都接近平均水平,所以两个教室学生的身高差异大致相同,接近于零。在第二种情况下,一个教室学生身高的方差偏低,而另一个教室学生身高的方差偏高,即表明学生的身高在平均水平上是不可比较的。在我们为这项研究构建的模型中,和在现实世界中许多应用一样,计算机假设这两个类别(在这里就是白人和黑人作者写作的文本)在它们的特征分布上具有大致相同的方差,因此具有可比性。
为了衡量每个初始类别的整体性,我们在已构建的语料库中检验了这种方差,以期厘清白人作者和黑人作者的文本是否以相同的方式使用其预测特征,以及他们是否通过类似的方式使用了其他类别的特征。按照上面的类比,每部小说都是一间教室,每位作者都是一名学生。事实上,我们发现这些数据的平均值是相当的。平均而言,黑人作者写作的小说使用该模型预测的黑人特征词的比率与白人作者写作的文本使用白人特征词的比率大致相同;同样,黑人作者的文本使用白人特征词的比率与白人作者的文本使用黑人特征词的比率也大致相同。然而,我们仍然想知道这些特征是否具有可比较的方差。
这就是我们的发现。黑人作者的小说使用黑人特征词的方差与白人作者的小说使用白人特征词的方差大致相同。然而,白人作者和黑人作者的小说在如何利用双方特征词方面存在着显著的差异。具体而言,黑人作者的小说使用白人特征词的方差比白人作者的小说使用黑人特征词的方差大40%。也就是说,黑人作者写作的小说呈现出更广泛的特征词参与性,这些特征词使我们能够区分白人作者和黑人作者写作的小说——而这正是我们构建模型的基础。这种参与性构成了一种内部差异,远远超出了我们在白人作者的小说文本中发现的差异[19]。
我们能从这些数据分析中得出什么结论?白人和黑人作者的小说类别是不可公度的。前者要比后者一致得多。与把教室分配给身高为五英尺和六英尺的学生不同,黑人作者的小说类别更适合描述为一些子类别的集合。这一结论支持黑人研究学者的学术观点,他们认为最近的移民动态给非裔美国人或黑人文学表面上的一致性带来了巨大的压力,同时也支持了肯尼斯·沃伦的观点[20],他认为这一范畴的一致性只是受吉姆·克劳(Jim Crow)法[21]施行的结果。但我们的结果更进一步表明这一类别自1950年代以来一直高度分散,甚至可能从更早的年代就已经这样了。同样,我们的结果扩展了“白人性”研究中的经典论点。驳斥了“白人性”是“无标记的”(unmarked)或“无内容的”(contentless)的说法,我们发现,“白人性”是相对一致的[22]。但事实上,根据埃里克·洛特[23]和莫里森的说法,这种一致性完全得自它与“黑人性”的关系。白人作者的小说集中在一个狭小的表达范围内,但只有通过他们对“黑人性”的表达才能体现出来。
尽管如此,虽然我们对分析范畴进行了这种分解,但是到目前为止,分析仍然依赖于这样一个假设,即白人和黑人是有意义的类别,即使其中一个被证明不如另一个连贯或稳定。如果拒绝这种观点,就会拒绝这些范畴的分析结果。例如,如果白人和黑人作者小说这些分析范畴不存在,那么所谓的白人特征词和黑人特征词就不存在。然而,我们可以进一步扩展我们的分解过程。
计算机分类使我们能够更全面地解构白人小说和黑人小说的类别。计算机不遵循严格的二进制逻辑,而是为每个文本分配一个介于0和1之间的概率,其中0对应文本由黑人作者编写的可能性,1对应文本由白人作者编写的可能性[24]。值0和1是被任意分配到它们各自的组的,并且交换值的分配不会影响实验的结果。如果文本得分高于0.5,则计算机将该文本标记为白人(white),如果文本得分低于0.5,则计算机将该文本标记为黑人(black)。因此,即使每个文本最终必须被分配一个二进制值,该框架中的身份(identity)也存在于一个频谱上。很少有小说的分数是0或1,大部分小说的分数都在0或1之间;有几部小说的得分在0.5左右——换言之,这是计算机完全不确定的领域。
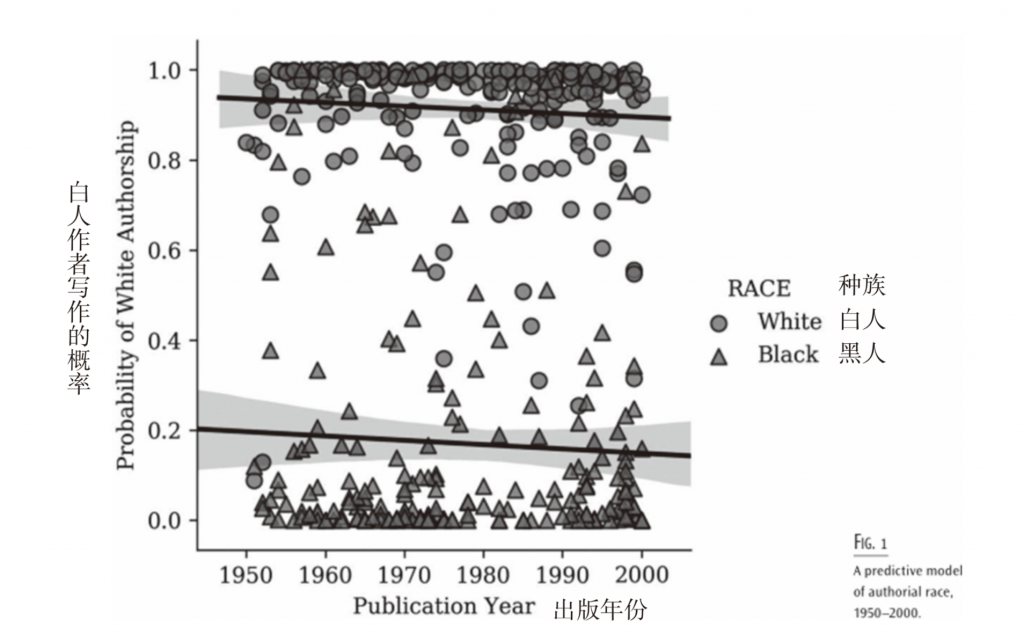
图1戏剧化地展示了计算机自身对这些类别的不稳定性的理解。每个标记代表一个文本:白人作者写作的小说用圆圈表示,黑人作者写作的小说用三角形表示。y轴对应于计算机对每个文本是由白人作者或黑人作者写作的概率的预测。标记所处的位置越高,其概率就越接近任意选择的值1,则表示越有可能是白人作者写作的文本;标记所处的位置越低,它就越有可能是黑人作者写作的文本。最后,我们添加了两条直线(由线性回归分析得出的“最佳拟合直线”)以可视化所有点之间的关系及其随着时间变化的大致趋势。目前,引人关注的不仅是白人作者和黑人作者之间进行区分的规模性和稳定性,而且还有一个事实,即按照其二进制标签(binary labels),许多文本的标记出现在其不应出现的位置。也就是说,少数圆圈落在黑人作者趋势线附近,大量三角形落在白人作者趋势线附近,这些被出人意料地放置的标记代表了计算机的错误识别(或错误分类)。
通常,计算机科学家将错误分类视为简单的错误——就像算法将垃圾邮件错误识别为真正的电子邮件一样。但是,当我们开始相信所采用的分析范畴类别可能非常不稳定,并且我们有兴趣测试这种可能性时,被错误分类的文本提供了有关导致这些类别不稳定原因的信息。分类错误的文本表明计算机已经变得混乱,但是我们可以将被错误分类的文本理解为计算机能可靠地理解文本的限度的标记,而不是将这种混乱视为计算机已犯错误的行为。分类错误的小说标志着使我们的小说分类变得不可靠的阈值。
到目前为止,按照更为传统的分类方法,我们认为这台计算机是一种标记区别的装置:区分白人和黑人作者写作的小说。然而,关注错误分类的文本,通过追踪它的对立面——它们的不确定性,而不是追踪分析范畴类别的可辨识,可以转换我们的分析视角。在这一时期,以及在更长一段时间里,白人和黑人作者之间的界限有多不明确?它是在增加还是在减少?白人作者的小说比黑人作者的小说更有可能是不确定的吗?我们检验了这些假设[25]。按照年份发现被错误分类的文本的数量是稳定的,因此,在我们研究期间,黑人作者和白人作者之间的不确定性是不变的。然而,我们发现黑人作者写作的小说比白人作家写作的小说被错误分类的可能性要大得多(几乎是白人作者的五倍)。这意味着,如果白人作者和黑人作者之间的区别是模糊的,那么这种不确定性更多地是由黑人作者的小说语料库所引起的。
三、文本细读:《乔凡尼的房间》(Giovanni’s Room)
对错误分类的文本的讨论能够帮助我们思考当前模型的局限性,以及如何对模型进行改进以应对这些局限性,同时也产生了对于我们的语料库的新见解。尽管如此,我们的分析仍略显粗糙。在已构建的模型中,我们讨论了白人和黑人作者身份之间的“阈值”,但是这个阈值在单个文本层级上是什么样的?具体而言,当我们谈及分析范畴类别的区分是视情况而变的时候,这又是什么意思?而被错误分类的作品的范畴类别让我们可以再次回到文本。那些在整个语料库范围内以一般形式存在的内容,在具体某些小说的层级上还可以获得粒度(granularity),依然可见。如果错误分类的总体类别表明计算机最初对黑人作者和白人作者的二进制理解受到了侵蚀,那么仔细分析一部被错误分类的小说就可以揭示出究竟是什么原因促使了这种本体论的破灭。
在最后这一部分,我们分析了一个具体的被错误分类的文本:小说《乔凡尼的房间》(1956)[26]。这是一部由著名的黑人作家詹姆斯·鲍德温创作的小说。我们为什么选择这部小说?因为黑人作者的小说比白人作者的小说更容易被错误分类,其导致了计算机“黑白分界线”(color-line)的混乱。在我们构建的语料库中收录的黑人作者的小说中,有六位作者至少有一部小说被正确分类,并同时至少有一部小说没有被正确分类。这些作者创作的小说让计算机特别“困惑”,使得这些小说文本标记同时存在于“黑白分界线”的两侧。这六位作者包括詹姆斯·鲍德温、罗伯特·博尔斯(Robert E. Boles)、塞缪尔·德拉尼(Samuel Delany)、休·霍尔顿(Hugh Holton)、查尔斯·约翰逊(Charles Johnson)和诺拉·德洛奇(Nora De Loach)。而鲍德温之所以从中脱颖而出,是因为计算机异乎寻常地确信他既是白人作者,也是黑人作者。它预测到有99.9%的可能小说《高山上的呼唤》(Go Tell It on the Mountain)是黑人作者所写,同时存在87.4%的可能小说《乔凡尼的房间》是白人作者写的。因此,分析后一部小说可以帮助我们理解原本有效地将白人作者和黑人作者的小说进行严格区分的界限是如何失效的。
读者即使对鲍德温的小说非常熟悉,对于战后的这种文学文本混淆了计算机分类的情况也几乎不会感到惊讶。小说《乔凡尼的房间》中人物角色几乎全是白人,并且故事主要发生在巴黎。它主要讲述了1950年代初居住在巴黎的美国白人男子大卫(David)与意大利男子乔凡尼(Giovanni)之间的感情暧昧关系。故事的重点在于大卫假装为一个异性恋者的性经历:尽管他和乔凡尼等男子有过多次交往,但仍然与一个美国女性保持着异性恋关系。故事的中心张力在于大卫无法承受在美国生活的压力,这种生活压力主要集中在战后中产阶级家庭生活的规范上,而他则十分渴望与欧洲男性建立浪漫关系,他无法调和这两者。这部小说在1956年首次出版时,对同性恋亲密关系的坦率描写引发了争议,自那以后,此部小说就被誉为“酷儿文学”的开创性作品。

1990年代末,学界研究普遍难以将其理解为一部大胆的黑人文学作品,例如梅·亨德森(Mae Henderson)肯定了这部小说的内容与“自相矛盾的主体性”的结合,也总体上发现这部小说通过对性别身份的关注而抹去“黑人性”[27]。然而,最近也有研究认为,小说《乔凡尼的房间》是通过其性别差异的比喻来“类比”种族差异[28]。在这部小说中,种族身份的互换(racial passing)以置换的形式出现,具体表现为性别身份的互换(sexual passing)。根据这一学术观点,鲍德温关注的是权力在社会中的规范表达,正如我们通过文本细读所显示的那样,这种权力源于欧洲白人的欲望理想,而黑人种族和同性恋都与这种理想格格不入。因此,此部小说明确地表达了对白人的批判和对种族差异的评价,即使它名义上被“性”取代了。阿里亚·阿布-拉赫曼写道,“我的焦点是鲍德温对‘白人性’的批判上,具体来说这种批判是通过他对酷儿性(queerness)种族化(racializing)效果的微妙暗示来进行的”[29]。
最近在关于对小说《乔凡尼的房间》的相关学术研究中,这种类似的思考以小说的人物阵容为出发点:黑人角色的缺席迫使人们对白人角色的性别、民族和阶级身份提出了质疑。因此,这一研究的大部分都集中在文本中对“黑人性”(blackness)的置换,以及由此而产生的“白人性”(whiteness)所带来的身份隐秘化。然而,这个文本也通过对一些特征进行与主题相关的安排来取代“白人性”,而我们所构建的模型则使用这些特征来构建白人作者身份。
我们如何把鲍德温的小说当作错误分类的文本进行文本细读?该模型确定了57个特征,这些特征在区分两类文本方面具有统计学意义。通过观察模型如何利用这些特征对小说《乔凡尼的房间》做出预测,这样我们可以更好地理解区分白人和黑人作者小说的阈值。但是,具体是哪些特征导致这部小说被计算机错误分类?我们可以将模型分配给每个特征的数值权重乘以它在文本《乔凡尼的房间》中出现的频率。此操作将返回计算机用来预测小说文本特征的排序列表,这反过来又暗示了一种与事实相悖的做法:如果我们将这些排序特征列表中的每一个都更改为它们在黑人作者写作的所有其他小说中出现频率的平均值(即我们期望在这些文本中看到的值),结果会是怎么样?想要让计算机预测小说《乔凡尼的房间》是由一位黑人作者写作的,需要更改多少特征词?我们发现模型中的57个特征词中有6个特征词必须改变,计算机才能将鲍德温的小说重新归类为黑人作者写作的小说。按照这些特征对文本错误分类的贡献率从高到低排序,分别是绝对的(absolutely)、非常(very)、当然(course)、震惊(appalled)、可能(might)和白人(white)。前5个特征是白人作者写作文本中的特征,经常出现在小说《乔凡尼的房间》里,而特征“白人”则预示着黑人作者的身份,但在文本中却出现得很少。
在继续分析之前,我们应该消除对此输出的错误解读。以下这种对这一结果的解读就是错误的:该文本通过大量使用某些措辞而使其“听起来”像白人作者写作的小说,并认为我们对小说进行了“去白人化”(unwhitened)以使其听起来更接近“黑人”。再次重申,计算机的思维不是本体论的。并不是说,白人作者的所有小说都是通过使用这样或那样的特征词来定义的,反之亦然。相反,计算机只是简单地衡量了这些给定分析范畴类别的社会建构的鲁棒稳定性,并指出是什么赋予了它们这样的活力。在接下来的分析中,我们试图理解为什么一份很简短的单词列表会对鲍德温的小说产生如此重大的影响,以及这些单词如何有助于我们理解小说《乔凡尼的房间》作为黑人文学作品在文学界的地位。
“白”(white)这个特征词会出现在这份列表上,是引人注目的,原因主要有两个:首先,与以往关注小说中“黑人性”缺失的文学研究不同,计算机关注的是“白”(white)的缺少。这一结果并不直接与现有的学术研究相矛盾,现有的学术研究常常集中在“白人性”和“黑人性”的共同作用方面。与之不同的是,我们为研究提供了另一个切入点。其次,计算机解释的是“白”(white)这个单词的缺少,而不是它的出现。在小说中这个单词只出现了26次,这意味着它不仅与大多数黑人作者的小说相比,这个词出现的频率较少,而且与我们所构建语料库中白人作者的普通小说相比,出现的频率也较少。这不仅仅是一个缺少标记“白人性”的案例,在这部小说中,人们强烈地感受到了“白”的缺少。
如何理解“白”(white)的缺少?我们首先需要研究这个词在小说中是如何为作者所使用的。它可以帮助鲍德温巧妙地用生动的语言描绘巴黎,在颜色和质地方面描述桌子、墙壁、收音机和衬衫的语句呈现爆炸式增长:
这里的确有年轻人,有六个人站在锌柜前喝着红葡萄酒和白葡萄酒,而还有一些人根本不再年轻。一个满脸麻子的男性和一个长相一般的女性正在窗户附近玩弹球机。有几个人坐在后面的桌子旁,由一个看起来非常干净的服务员招待。在黑暗中,肮脏的墙壁,布满锯屑的地板,服务员的白色夹克像雪一样闪闪发光。在这些桌子后面,人们可以瞥见厨房和那个粗鲁、肥胖的厨师。他笨拙地走来走去,就像一辆超载的卡车一样,戴着一顶高高的白色帽子,嘴唇间夹着一支雪茄[30]。这一幕发生在故事早期。故事主角是乔凡尼、大卫和纪尧姆(Guillaume),其中纪尧姆是一个年长的同性恋男子,他们正在巴黎的一家波西米亚餐厅吃饭。这个场景使用了大量的形容词,在干净与肮脏、纯洁与粗鄙之间形成了一系列鲜明的对比。乍一看,单词“白”(white)的使用似乎有助于凸显小说的明暗象征意义。
继续阅读小说,不难发现其中一个场景对乔凡尼小团体的性经济(sexual economy)进行了戏剧化处理。正如评论家所指出的那样,这个故事产生的社会背景是年长的、富裕的巴黎男子与年轻的、贫困的男子之间用食物换取性的行为。然而,我们发现这种交换行为是很微妙的,不能简单解读为剥削。酒吧里的男孩们都有代理:当顾客们走进餐厅时,每个人都会评估下,“已经计算出他和他的同伴接下来几天需要消费多少钱……”[31]虽然经济拮据,但是在这一场景中的年轻男孩们互相照顾,并有意识地与年长的男子协商其关系。
仔细观察小说中描述的白色物体,就能揭示出这种经济是如何运作的。这件白色的夹克让大卫感到震惊,当夹克的“洁白”与房间中的“脏墙”和“布满锯屑的地板”形成鲜明的对比时,而这瞬间的闪回手法揭示了有生气的场景的两分法(纯洁/粗鄙、年轻/年长)。除了其象征意义外,这件夹克还清楚地表明了这种经济是如何体现其物质性的。年长的男性购买白酒,然后为年轻的男孩们提供一顿饭,这使得随后的面对面互动成为可能。当男孩们计算出乔凡尼的“价值”后,他们会思考自己想要得到什么:“剩下的唯一问题是,他们是会跟他用牛(vache)换呢,还是会用鸡(chic),但他们知道他们很可能会用牛(vache)。”[32]这一交换的循环仍在继续。文章中的白色物体有助于激活这一过程,但是这个循环很快就会越过那些原始的事物。

事实上,“白”(white)这个词最引人注目的地方还在于它从小说中消失的速度很快。故事结束时,这个词已经完全从文本中消失了。正如我们在上文中看到的那样,文本中经常出现的白色物品是用以提示一组社交互动的,但文本很快就不再关注这些物品了,而是更多地关注社交互动。这种倾向有助于解释强化词(intensifier)在文本中相对突出的原因——它们用来阐述和定义那些社会互动(social interactions):绝对(absolutely)、非常(very)和当然(of course)。事实上,“非常”(very)这个词可能是小说中最显著的词语,出现的次数超过200次,如果用这个词预测出一本小说是白人作者的作品,平均来说,这个词的频率只需要这个文本中的不到三分之一即可。这个词语出现在所有主要人物的对话情境中,也出现在大卫写给读者的叙述话语中。例如,在乔凡尼对大卫说的连续两句话中,他是“一个非常(very)迷人、英俊并且具有绅士风度的男子”,这使维持他们的关系变得“非常(very)简单”,即使大卫的未婚妻回到巴黎之后也是如此。另外,大卫以对乔凡尼的问题简短的回应,断然拒绝了他对他们一起生活的设想。他是否预料到自己会在没有海拉(Hella)的情况下去约会其他人?“当然是”(Of course)。她是否让他承认除了与她有关的事情以外他所做的一切?“当然不是”(Of course not)[33]。
或者我们关注一下大卫早年的一个关键时刻,当大卫最终认识到他的父亲同是人,而不是一个充满敌意的父亲时:“我父亲的脸变了。它变得极其古老,但同时又变得绝对地年轻且无助。我记得,当我意识到我的父亲一直在受苦,且仍然在受苦的时候,我对发生在我体内并身处这场寂静而寒冷的风暴中心而感到绝对地震惊”[34]。计算机识别的过程取决于一个特定的强化词“绝对地”(absolutely),这一强化词很快地在文本中连续出现两次。大卫和他的父亲基本上是通过这个词语产生互动:“绝对地”这个词首先用来描述其父亲的脸,然后用以刻画大卫自己的反应和内心感受。大卫和他的父亲通过这种强烈情感的镜像(mirroring)进行有意义的互动。
在鲍德温小说的开头部分,计算机已经开始关注到“白人性”(whitness)暗示着作者对某一事物或空间的潜在描述,但很快则通过对其他类型叙述的关注取代了这种类型的描述,即通过运用某些词语强化对事物的描述(“非常”[very],“当然”[of course]),而不仅仅是描述事物。这一行为追踪到了“白人性”的消失。但是,“白人性”并不是简单地消失,而是以隐秘的形式重新出现。细想导致这部小说被错误分类的词语列表上的最后一个词:震惊(appalled)。这个词在小说中只出现过一次,但是它对让计算机将小说《乔凡尼的房间》错误归类为一位白人作者所写的小说却产生了重大的影响。如果一个词语与小说中所有其他词语的关系不同于它在语料库中出现在其他小说文本中的形式,那么它就可以导致这样的差异。在这个文本中,这个词语出现在小说中描述大卫性格的关键时刻。与20世纪中期关于同性恋研究的心理学话语相呼应的是,这部小说密切关注大卫与父母之间令人烦恼的关系,又一次地,是他的父亲激活了他强烈的自我意识,但现在却是一种消极的自我意识:“我们不像父子,我父亲有时骄傲地说,我们像朋友一样。我想我父亲有时真地相信这一点,但我从来没有。我不想做他的朋友,我想做他的儿子。我们之间传递的那种男性的坦率使我精疲力竭和震惊”(appalled)[35]。在大卫的父亲那里缺少一种充满男子气概的角色榜样。他已经开始接受这一点(如上所述),但是现在的问题是,曾经以友谊为基础的可行的父子关系如今变得无效,甚至令人反感。而这个词语的词源就很能说明问题:“appall”这个词源于中古法语(Middle French)的一个词语“apalir”,意思是“变得苍白,使苍白”(即英语中的“appall”)。[36]在这里,当大卫发展出一种与标准男性气质相悖的、有问题的关系时,也是他变“白”(white)的那一刻。但是“白人性”本身没有被指称出来,也不能被直接指称出来。这仅仅是影射大卫与他父亲关系破裂的结果。虽然不能被直接指向,但它就在那里。
我们在细读过程中强调了“白人性”被取代,也许和“黑人性”一样,并最终从文本中消失。但细读也确定了它的语义变异(semantic mutations),就像“白人性”在那里显现而又不是在那里一样,它隐藏在大卫对其父亲的“可怕”(appalled)恐惧中。这种远读和文本细读相结合的方式揭示了原本隐形的语言效果,暴露了白人性的变异或取代,从而为现有的学术研究做出了贡献。我们还没有读到任何学者注意到这部小说中“震惊的”(appalled)这个词的重要性。如果没有计算机的帮助,我们也不会注意到它。然而,一个看似偶然的词却最终暴露了文本中白人性具有决定性意义的重塑。
通过使用这种计算方法可以对小说《乔凡尼的房间》进行更多元的解读,但这项研究旨在强调以下几点:计算机可以确定,作为社会构建的范畴类别,白人作者和黑人作者的小说是显著不同的。但是将它们分开的那条线,最初看起来十分牢固(准确率达92%),但同时也是脆弱的、易变的。为了阐明此研究方法的二进制逻辑,在57个特征中,只有6个特征需要调整。具体而言,尤其是词语“震惊的”(appalled),似乎既是在整个语料库的规模上、又是在一个具体的篇章里面,对我们如何理解白人作者和黑人作者写作的小说范畴分类,都会产生重大的影响。
结 论
通过文本细读得出的结论为我们反思远读方式的局限性提供了决定性的机会。在这里,我们回到之前担忧的问题,即白人作者和黑人作者小说的范畴类别消除了历史的和交叉的身份定义方式。而基于细读的研究颠覆了计算机的“黑白”逻辑,而这一颠覆直接源于小说对酷儿性(queerness)的表达。鲍德温的小说打破了(queer)计算机的“黑白分界线”,挑战了我们最初对白人作者或黑人作者的小说的范畴分类规则,这种“黑白”范畴分类原则必然会遮蔽对社会身份的更复杂、更交叉的观点。在目前的形式下,我们的数据和模型还不够鲁棒和强大,并不足以处理这种交叉性。
但是我们或许可以想象这一研究的改进版本,既考察种族身份认同又考察性别身份认同,在数据和模型构建中同时将这两个方面纳入进来。然后,不仅追踪计算机对白人作者和黑人作者的小说范畴类别区分的偶然性,还追踪小说进行异性恋和同性恋,或者更广泛地说是酷儿(queer)[37]归类的偶然性,以及这些偶然性如何相互关联。事实上,本文旨在发展一套适合于分析文学中的种族和种族话语的远读的批判范式。通过设想一种自反的方法,使计算机能够识别出被忽略的内容,同时也能提供新的洞见和研究契机。
—————————————————————————————————————————————————————————————
Race and Distant Reading
Richard Jean So, Edwin Roland
Abstract: With the penetration and application of digital technology in the field of humanities research, the “distant reading” method proposed by Franco Moretti is inspiring for text analysis.This paper uses a combination of distant reading and close reading of the text, and aims to link the two cultural-literary analysis methods that have not yet been fully integrated, and develop a set of critical paradigms suitable for the analysis of race and racial discourse in literature. However, on the one hand, diction and syntax, or style and narrative, with race can easily create stereotypes; on the other hand, there are still many existing digital corpora and tools that cannot record race differences. In order to break through this limitation, this research is mainly divided into the following three parts: First, It focuses on post-war American novels, constructs a corpus of novels by black/white authors, and builds models (phrases, syntax and narration) to analyze the overall text characteristics of novels in the corpus, and to form a professional vocabulary; the second is from the perspective of analysis and model criticism, mainly to observe how computers “understand” the racial differences in the binary (white/black) frame; the third is to explore the novel Giovanni’s Room through close reading of the text to reveal the original invisible language effect, exposing the variation or substitution of whiteness. Finally, this article conceives a reflexive method that enables the computer to recognize the neglected content, while also providing new perspectives and research opportunities.
Keywords: Race; Distant Reading; Close Reading; Literary Style; Identity; Model Critique
—————————————————————————————————————————————————————————————
编 辑 | 姜文涛
注释:
[1]See Ted Underwood“, Machine Learning and Human Perspective,”PMLA, Vol. 135, No. 1, 2020.
[2]Franco Moretti, Distant Reading, Verso, 2013, p.48.
[3]Natalie Houston“, Towards a Computational Analysis of Victorian Poetics,”Victorian Studies, vol. 56, no. 3, 2014, pp. 498-510.
[4]Tanya E. Clement,“‘A Thing Not Beginning and Not Ending’: Using Digital Tools to Distant-Read Gertrude Stein’s The Making of Americans,”Literary and Linguistic Computing, vol. 23, no. 3, 2008, pp. 361- 381.
[5]Sarah Allisonet et al.“, Style at the Scale of the Sentence,”Stanford Literary Lab, pamphlet, June 5, 2013, https://litlab.stanford.edu/LiteraryLabPamphlet5.pdf.
[6]Andrew Piper, Eva Portelance,“How Cultural Capital Works: Prizewinning Novels, Bestsellers, and the Time of Reading,”Post, vol.45, May 10, 2016, http://post45.research.yale.edu/2016/05/how-cultural- capital-works-prizewinning-novels-bestsellers-and-the-time-of-reading/.
[7]Tara McPherson,“Why Are the Digital Humanities So White? or, Thinking the Histories of Race and Computation,”in Matthew K. Gold ed., Debates in the Digital Humanities, University of Minnesota Press, 2012, pp. 139-160.
[8]Kim Gallon,“Making a Case for the Black Digital Humanities,”in Matthew K. Gold and Lauren F. Klein eds., Debates in the Digital Humanities 2016, University of Minnesota Press, 2016, pp. 42-49.
[9]Lauren F. Klein,“Distant Reading after Moretti,”Arcade: Literature, Humanities, and the World, https:// arcade.stanford.edu/blogs/distant-reading-after-moretti.
[10]Roopika Risam“, Navigating the Global Digital Humanities: Insights from Black Feminism,”in Matthew K. Gold and Lauren F. Klein eds., Debates in Digital Humanities 2016, University of Minnesota Press, 2016, pp. 359-367.
[11]不同体裁的220部小说是否能够提供足够的数据以产生有意义的结果?比如,与我们研究期间白人作者出版的数万部小说进行比较。虽然理论上对抽样的讨论超出了我们研究的范畴,但我们指出了类似计算机学习技术的最新应用,这些技术在使用和我们构建的语料库规模类似的情况下仍能获得可靠的结果。可参见:Andrew Piper, Eva Portelance,“How Cultural Capital Works: Prizewinning Novels, Bestsellers, and the Time of Reading,”Post, vol. 45, May 10, 2016, http://post45.research.yale.edu/2016/05/how-cultural- capital-works-prizewinning-novels-bestsellers-and-the-time-of-reading/; Hoyt Long, Richard Jean So, “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning,”Critical Inquiry, vol. 42, no. 2, Winter 2016, pp. 235-267; Ted Underwood, Jordan Sellers,“The Longue Durée of Literary Prestige,”Modern Language Quarterly, vol. 77, no. 3, 2016, pp. 321-344。在上述各实践案例中,作者所代表的每个类别包括不超过200份的文本或大约1,500万个单词。而我们所构建的语料库超过了这两个阈值。
[12]See Matthew Frye Jacobson, Whiteness of a Different Color: European Immigrants and the Alchemy of Race, Harvard University Press, 1999.
[13]See Nell Irvin Painter, The History of White People, W. W. Norton, 2010.
[14]“Mulatta”是指父母一方为黑人、一方为白人的人,或者更泛一些,是指先祖有欧洲人与非洲人混血的人。——译注,参考维基百科“mulatta”词条。
[15]此统计模型采取逻辑回归(logistic regression)算法进行二进制分类。通过使用Python中的计算机学习包scikit-learn进行实践。为了保证模型的通用性,我们使用了L1正则化,该模型选择了少量特征用于预测,并通过十折交叉验证(tenfold cross validation)确定了一个近似最优的正则化系数(C=1.0)。
[16]这些特征的产生主要归功于由戴维·巴曼(David Bamman)开发和发布的BookNLP管线(Pipleline)。术语频率是从管线“OriginalWord”输出的小写条目列表中列出的。虽然在这一阶段停止词(Stopword)经常被删除,但仍将其纳入到整个模型中,因为它们被理解为可以对体裁和作者创作风格进行标记的特征词。词性标签(Part-of-speech tags)是从管线的“POS”输出中制成的,该输出按照宾州树库(Penn Treebank)格式报告以进行标签,并依赖于斯坦福POS标注器(词性标注器)。然后,将其视为句子边界内连续标记的二元语法技术(bigrams)。叙述特征包括从“ner”和“sst”输出列表中生成的命名实体识别(Named Entity Recognition, NER)和超感标记器(Super Sense Tagger, SST)中的列表频率。该管线使用斯坦福NER标记器和Wordnet超感标记器(SST)。例如,这些标签可以引用小说中的任何人物(PERSON)或地点(LOCATION)、物品(OBJECT)或动作(ACTION)。除此之外,我们还计算了由对话组成的文本的占比(来自“inQuotation”输出)、由人物提及组成的文本的占比(即来自“characterId”输出的总字符空间),以及按文本长度标准化的唯一字符的数量(也来自“characterId”输出)。请注意,在构建任何模型之前,每种特征均经过L1标准化(L1-normalize),以最大程度地减少文本长度的影响。然后将所有要素转换为标准单位,以便相互比较分析。
[17]我们提到的显著特征在模型中具有非零权重,并通过了Z检验,表明在白人作者和黑人作者之间,它们具有不同的均值。在这种情况下,以及在本文中所有其他具有统计意义的测试中,我们都采用95%的置信度阈值(confidence threshold)。此外,在我们考虑的所有情况下,都是在多重比较环境中对显著性进行检验,因此我们通过邦费罗尼校正(Bonferroni correction)调整了置信度。实际上,我们要求p=0.05/[观察次数]。
表1注释2:如果我们将白人作者的大型小说语料库按照体裁(畅销书、获奖小说、科幻小说和侦探小说)进行划分,那么每个子语料库即总共包括180部小说,相比之下,黑人作家的小说样本为180部。
[18]See Gary Okihiro, Margins and Mainstreams: Asians in American History and Culture, University of Washington Press, 2014.
[19]黑人作者使用白人特征词的平均频率约为-0.32;白人作者使用黑人特征词的平均频率为-0.31。请注意,特征频率使用标准单位,因此上面的值表明两组作者使用另一组特征的频率略低于语料库的平均频率。z检验无法拒绝零假设,即黑人作者使用白人特征词的平均频率与白人作者使用黑人特征词的平均频率不同(p=0.7)。然而,当检验黑人作者写作的文本中使用白人特征词的方差与白人作者写作的文本中使用黑人特征词的方差时,z检验在高置信度下拒绝了零假设(p≤0.01)。在这种情况下,发现黑人作者文本中使用白人特征词的方差(σ2=0.42)比白人作者文本中使用黑人特征词的方差(σ2=0.3)大约高40%。
[20]See Kenneth Warren, What Was African American Literature? Harvard University Press, 2012.
[21]吉姆·克劳法泛指1876年至1965年间美国南部各州以及边境各州对有色人种(主要针对非洲裔美国人,但同时也包含其他族群)实现种族隔离制度的法律。——译注
[22]See Toni Morrison, Playing in the Dark: Whiteness in the Literary Imagination, Harvard University Press, 1992.
[23]See Eric Lott, Love and Theft: Blackface Minstrelsy and the American Working Class, Oxford University Press, 1993.
[24]文本属于给定范畴的概率是逻辑回归(logistic regression)的一个固有特征,这是以前的文学研究所接受的内容,我们在此强调这一点。通过留一交叉验证(leave-one-out cross validation),为每个文本分配概率,其中指定作者的文本在测试期间被搁置,然后接受预测。
[25]采用逻辑回归进行检验。我们创建了一个对应于一部小说在1975年前/后出版的二进制虚拟变量(binary dummy variable),并且随着作者种族身份的出现,我们将这些变量回归到另一个二进制虚拟变量中,这些变量与小说是否已经按照模型正确分类(即:日期+种族~正确)相对应。发现只有作者种族身份显著(p≤0.01),并且它有一个似然比(likelihood ratio),则黑人作者写作的小说分类错误率增加了4.58倍。
[26]See James Baldwin, Giovanni’s Room, Random House, 2013.
[27]Mae Henderson“, James Baldwin: Expatriation, Homosexual Panic, and Man’s Estate,”Calalloo, vol. 21, no. 1, 2000, p. 313.
[28]Aliyyah I, Abur-Rahman,“‘Simply a Menaced Boy’: Analogizing Color, Undoing Dominance in James Baldwin’s Giovanni’s Room,”African American Review, vol. 41, no. 3, 2007, p. 477.
[29]Aliyyah I. Abur-Rahman,“‘Simply a Menaced Boy’:Analogizing Color, Undoing Dominance in James Baldwin’s Giovanni’s Room,”p. 480.
[30]James Baldwin, Giovanni’s Room, p.50. 重点由本文作者加粗。
[31]James Baldwin, Giovanni’s Room, p.53.
[32]James Baldwin, Giovanni’s Room, p.53.
[33]James Baldwin, Giovanni’s Room, p. 47. 重点由本文作者加粗。
[34]James Baldwin, Giovanni’s Room, p.19. 重点由本文作者加粗。
[35]James Baldwin, Giovanni’s Room, p.17. 重 点 由 本 文 作 者 加 粗。原 文 如 下:“We were not like father and son, my father sometimes proudly said, we were like buddies. I think my father sometimes actually believed this. I never did. I did not want to be his buddy; I wanted to be his son. What passed between us as masculine candor exhausted and appalled me”。——译注
[36]“Appall, Verb,”Merriam-Webster Unabridged, Merriam Webster, 2019, http://unabridged.merriam- webster.com/unabridged/appall.
[37]“酷儿”(Queer)由英文音译而来,原是西方主流文化对同性恋的贬称,有“怪异”之意,后被性的激进派借用来概括他们的理论,含反讽之意。1990年代以来,黑人文学理论一个新的发展方向是酷儿理论(black queer theory,又可译为“怪异理论”)的出现。——译注
原刊《数字人文》2020年第3期,转载请联系授权。
本文译自Richard Jean so, Edwin Roland,“Race and Distance Reading,”PMLA, vol. 135, nol. 1, 2020, Published by the Modern Language Association of America. Translated and published in Chinese with author’s permission.
作者简介:
埃德温·罗兰(Edwin Roland),芝加哥大学文学硕士,加州大学圣巴巴拉分校英语专业博士生,研究领域包括美国文学和新媒体。他曾担任伯克利数字人文倡议(Digital Humanities at Berkeley Initiative)组织数字文学研究协调员。